2020.07.04更新: 加入使用Transformers的Bert的例子,见github: pytorch-bert-elmo-example
2019.4.3更新:新增使用AllenNLP的ELMo做文本分类的例子说明:详见github: Pytorch-ELMo
Bert/ELMo不同于word2vec、glove,属于上下文词向量模型, 可以很方便用于下游NLP任务中。
- ELMo基于LSTM, 来自《Deep Contextualized Word Representations》
- Bert基于Transformer, 来自《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
ELMo简介
ELMo使用双层BiLSTM来训练语言模型,创新是线性组合不同层的word vectors, 作为最终的word representation. 核心公式:
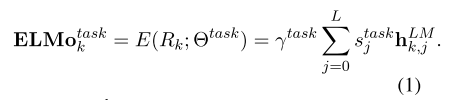
- 第一层是普通的word embedding 可以用wrod2vec或者glove来得到,或者使用character level得到token embedding》 这部分是general embedding,上下文无关。文中使用的character level的CNN+Highway.
- 后面连接两个biLSTM 去encode 输入(同时也有残差连接), 每一层LSTM得到的输出(隐状态) 作为每个词的上下文相关的word vectors.
- 这样每个词就会有(L+1)个词向量,L为biLSTM的层数.
- 词向量的线性组合,针对不同的任务,不同层的向量做不同的权重加和。 其中权重s是一个维度为L的vector,参与训练。
因此ELMo的基本输入单元为句子,每个词没有固定的词向量,是根据词的上下文环境来动态产生当前词的词向量,常见的场景可以较好解决一词多义的问题,这一点跟word2vec与glove等通用词向量模型是不同的。
Pytorch版ELMo (Allennlp)
这个是官方的ELMo的版本,基于Allennlp或者pytorch。官方文档给的example有些迷惑,这里记录一番。 Allennlp的ELMo的API为allennlp.modules.elmo.Elmo, 完整的输入参数参见文档,几个比较重要的如下:
- options_file : ELMo JSON options file
- weight_file : ELMo hdf5 weight file
- num_output_representations: The number of ELMo representation layers to output.
- requires_grad: optional, If True, compute gradient of ELMo parameters for fine tuning.
其中一个关键的参数为num_output_reprensenations 文档描述不太清楚,具体可以看见在github提的issue和pr。 这个num_output_representation 一开始理解这个参数是输出三层中前几层,但是其实并不是这样,因为这个参数的取值可以是任意正整数。 我们知道ELMo文章中最后词向量表示即公式1计算的是三层表示的线性加权,针对不同的任务,可能会有不同的加权比例。 因此num_output_representation 表示输出多种线性加权的词向量,即多个公式1产生的词向量。 而Allennlp的ELMo 并不直接提供中间的三层输出(char-cnn, lstm-1, lstm-2),不过可以通过稍微修改源代码的方法获得。
再看例子如下: 1
2
3
4
5
6
7
8
9
10
11
12
13from allennlp.modules.elmo import Elmo, batch_to_ids
options_file = "options.json" # 配置文件地址
weight_file = "weights.hdf5" # 权重文件地址
# 这里的1表示产生一组线性加权的词向量。
# 如果改成2 即产生两组不同的线性加权的词向量。
elmo = Elmo(options_file, weight_file, 1, dropout=0)
# use batch_to_ids to convert sentences to character ids
sentence_lists = ["I have a dog", "How are you , today is Monday","I am fine thanks"]
character_ids = batch_to_ids(sentences_lists)
embeddings = elmo(character_ids)['elmo_representations']len(embeddings) == 1,里面的一个元素则是论文中公式1产生的ELMo的词向量, shape为[batch_size, max_length, 1024], 即:[3, 9, 1024], (根据配置文件不同,最后维度可能不同, 参考预训练权重)。
如果上述参数1改为2,则表示产生两个权重不同的ELMo词向量,可以用于不同任务的词向量。
一般单任务下,我们直接使用1就可以了。
tensorflow版 ELMo
首先载入ELMo的方法很简单,直接load tfhub即可:
1 | import tensorflow as tf |
调用方法也很简单: 1
2sentence_lists = ["I have a dog", "How are you , today is Monday","I am fine thanks"]
output = embed(sentence_lists, as_dict=True)1
2
3
4
5
6
7
8{
'default': <tf.Tensor 'module_apply_default_6/truediv:0' shape=(3, 1024) dtype=float32>,
'elmo': <tf.Tensor 'module_apply_default_6/aggregation/mul_3:0' shape=(3, 9, 1024) dtype=float32>,
'lstm_outputs1': <tf.Tensor 'module_apply_default_6/concat:0' shape=(3, ?, 1024) dtype=float32>,
'lstm_outputs2': <tf.Tensor 'module_apply_default_6/concat_1:0' shape=(3, ?, 1024) dtype=float32>,
'sequence_len': <tf.Tensor 'module_apply_default_6/Sum:0' shape=(3,) dtype=int32>,
'word_emb': <tf.Tensor 'module_apply_default_6/bilm/Reshape_1:0' shape=(3, 9, 512) dtype=float32>
}
解释下这些字段的意思:
word_emb: ELMo的最开始一层的基于character的word embedding, shape为[batch_size, max_length, 512]lstm_outpus1/2: ELMo中的第一层和第二层LSTM的隐状态输出,shape同样为[batch_size, max_length, 1024]elmo: 对应文章中的公式1,每个词的输入层(word_emb),第一层LSTM输出,第二层LSTM输出的线性加权之后的最终的词向量,shape为[batch_size, max_length, 1024],此外这个线性权重是可训练的。default: 前面得到的均为word级别的向量,这个选项给出了简单使用mean-pooling求的句子级别的向量,即将上述elmo的所有词取平均,方便后续下游任务。sequence_len输入中每个句子的长度
一般情况使用output ['elmo'] 也就是Allennlp版本的elmo_representations, 即可得到每个词的ELMo 词向量,即可用于后续的任务,比如分类等。
Bert
Bert使用Transformer来代替LSTM, 具体原理这里不再赘述了,网上非常多的资料,给出几个:
- 讲解理论
- http://jalammar.github.io/illustrated-transformer/
- https://www.youtube.com/watch?v=ugWDIIOHtPA
- 【全面拥抱Transformer】https://zhuanlan.zhihu.com/p/54743941
- 【[整理] 聊聊 Transformer】https://zhuanlan.zhihu.com/p/47812375
- http://jalammar.github.io/illustrated-bert/
- https://www.youtube.com/watch?v=Bywo7m6ySlk
- 实现介绍
- https://nlp.seas.harvard.edu/2018/04/03/attention.html
- 调用fine-tuning: https://github.com/huggingface/transformers
- pre-trained : https://github.com/google-research/bert
- pre-trained: https://github.com/dbiir/UER-py