2018.12.2更新:使用
neo-admin import导入全量的Aminer数据到Neo4j.
- 首先用这个脚本从原始的154个txt中提取出字段,保存为
neo-admin import所需要的格式.格式要求, - 脚本会对每个txt文件,均产生parper,org,author, p-o,p-a, a-o六个csv文件,然后归类成如下目录:
1
2
3
4
5
6
7
8
9
10
11
12$ tree | grep -v 'csv'
.
├── nodes
│ ├── author
│ ├── org
│ └── paper
└── rels
├── author_org
├── cite_relation
└── paper_author
8 directories, 930 files - 使用
neo-admin import导入:1
2
3
4
5
6
7
8
9bin/neo4j-admin import
--ignore-duplicate-nodes=true --ignore-extra-columns=true \
--ignore-missing-nodes=true --high-io=true \
--nodes /data/out/nodes/org/.*.csv \
--nodes /data/out/nodes/author/.*.csv \
--nodes /data/out/nodes/paper/.*.csv \
--relationships /data/out/rels/author_org/.*.csv \
--relationships /data/out/rels/cite_relation/.*.csv \
--relationships /data/out/rels/paper_author/.*.csv
最终导入输出: 1
2
3
4
5
6IMPORT DONE in 1h 25m 39s 635ms.
Imported:
257487502 nodes
1054515383 relationships
1497110211 properties
Peak memory usage: 17.12 GB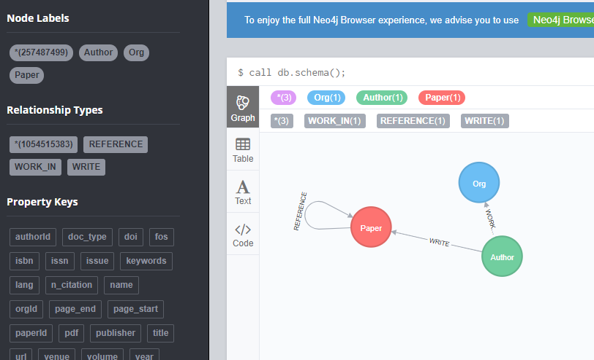
机器配置:
- CPU:E5-2650 v4
- 内存: 128G
前面一篇介绍了Neo4j一些比较基础的用法。这一篇笔记主要记录下在导入一个大数据集Aminer中MAG论文数据所遇到的一些问题。
数据集介绍
首先关于论文数据集的描述可以在 Aminer_Open_Academic中查看,这里简单介绍一下。 有两套数据,一个是Aminer Papers, 是清华大学整理发布的论文集,MAG Papers是微软学术发布的论文数据集。 我们这里选取了MAG的部分数据集来测试导入到Neo4j中。 MAG数据集一共有9个压缩包,其中每一个压缩包里面有20个txt文件,每个txt文件中每行代表一篇论文,用json表示,mid 为论文唯一id,可以作为主键使用。除了论文的基本属性比如发表时间,摘要,doi号等,需要注意的两个属性为:
- 作者列表:
{"name": "org":}给出了作者的姓名及所在机构。 - 参考文献列表:
[mid]给出了引文的id号
数据示例如下: 1
2
3
4
5
6{
"title": "Activation of Protein Kinase C (PKC) by 3,4-Methylenedioxymethamphetamine (MDMA) Occurs Through the Stimulation of Serotonin Receptors and Transporter", "lang": "en", "n_citation": 50, "year": 1997,
"authors": [{"name": "M.D. H.Kenneth Kramer", "org": "Department of Psychiatry, New York University, New York, New York USA"}, {"name": "Jose Conrado Poblete", "org": "New York University Medical Center and Department of Biology, New York University, New York, New York USA"}...],
"references": ["02a308b0-c362-41b3-94ac-8385992a77a3", "057af91d-eb27-449c-bc2a-ce1ba41b60c8", "0b97d99a-4f4e-4ed6-b0e0-594367443594", "0e62c328-9944-4cac-bff9-12f310c829b1"],
"abstract": "...", "issue": "3", "page_end": "129", "publisher": "Nature Publishing Group", "url": ["http://www.nature.com/doifinder/10.1016/S0893-133X(97)00026-2", "http://cat.inist.fr/?aModele=afficheN&cpsidt=2795397"..], "doi": "10.1016/S0893-133X(97)00026-2", "id": "0000017a-4ca6-4860-87fa-2f8d742267dd", "keywords": ["second messenger", "transporter", "voie intraperitoneale"", "fos": ["Biology", "Endocrinology"]
}1
2
3
4
5
6
7
8
9# 节点
- Paper: 论文及其字段属性
- Author: 作者:姓名
- Org: 组织:名字
# 边
- 引文关系: Paper-Paper
- 写作关系: Author-Paper
- 隶属关系: Author-Org
导入Neo4j
这里我们作为测试,只用了一部分数据集,使用了10个txt文件的论文数据集,即1000万篇论文,数据量大概18G,时间可以接受,在尝试过几种方法之后,基本上可以20分钟左右导入完成。 下面这个遇到的问题及解决方案等记录一下。
最开始利用上篇博客的导入Json的方法来直接导入:(事先均建立节点Label索引) 1
2
3
4
5
6
7call apoc.load.json("file:/mag_papers_0.txt") yield value as paper
CREATE (p:Paper{id:paper.id})
set p.lang=paper.lang,p.doc_type=paper.doc_type,p.doi=paper.doi,p.isbn=paper.isbn,p.fos=paper.fos,p.url=paper.url,
p.abstract=paper.abstract,p.year=paper.year,p.publisher=paper.publisher,p.references=paper.references,
p.keywords=paper.keywords,p.title=paper.title,p.pdf=paper.pdf,
p.n_citation=paper.n_citation,p.venue=paper.venue,p.page_start=paper.page_start,
p.page_end=paper.page_end,p.volume=paper.volume,p.issue=paper.issue,p.issn=paper.issn1
2
3
4
5
6
7
8
9call apoc.load.json("file:/mag_papers_0.txt") yield value as paper
CREATE (p:Paper{id:paper.id})
set p.lang=paper.lang,p.doc_type=paper.doc_type,p.doi=paper.doi,p.isbn=paper.isbn,p.fos=paper.fos,p.url=paper.url,
...
with paper
UNWIND paper.author as author // 展开Authorlists
MERGE (a:Author{name:author.name} // 创建作者节点
MERGE (o:Org{name: author.org} // 创建组织节点
MERGE (a)-[WORK_IN]->(o) //创建 隶属关系
然而...
不过即使这样, 跑着1000万的节点数据, 运行几分钟后,就会crash掉... 连不上服务器,CPU也不再并行,仅仅100%运行,初步猜想可能是因为数据集太大,一次向导入可能会超内存,因为我们使用100万的节点 是可以很快导入的。 于是换了策略,使用apoc的分批导入call apoc.periodic.iterate: 1
2
3
4
5
6
7
8
9call apoc.periodic.iterate(
'
call apoc.load.json("mag_papers_0.txt") yield value as paper return paper',
'
CREATE (p:Paper{id:paper.id})
set p.lang=paper.lang,p.doc_type=paper.doc_type,p.doi=paper.doi,p.isbn=paper.isbn,p.fos=paper.fos,p.url=paper.url,
....//略写
',
{batchSize:50000, iterateList:true, parallel:true});
下面开始考虑导入论文的引文关系, 同样遇到了问题。 开始直接从paper.references属性中导入: 1
2
3
4MATCH (n:Paper)
UNWIND n.references as F
MATCH (m:Paper {id: F})
MERGE (n)-[r:CITES]->(m)apoc.periodic.iterate 同样遇到了问题, 百思不得其解。
后来的解决方法是,单独写了脚本文件,将引文关系,作者和结构信息,及隶属关系均提取出来,直接用Python处理千万级别的文件,速度很快,最后导成csv文件,如引用关系: 1
paper1id, paper2id
1
2
3
4
5
6
7
8call apoc.periodic.iterate("
call apoc.load.csv('paper_cite_relation.csv') yield list as line
MATCH (p1:Paper{id:line[0]}), (p2:Paper{id:line[1]}) return p1, p2
",
"
CREATE (p1)-[:CITE]->(p2)
",
{batchSize:50000, iterateList:true, parallel:true})
最后导入作者和机构信息,基本上照猫画虎即可,这里举一个paper-author的例子: 1
2
3
4load csv with headers from "file:/p_a.csv" as line
FIELDTERMINATOR ","
match (a:Author{name:line.name}), (p:Paper{id:line.pid})
CREATE (a)-[:WRITE]->(p)
这样总体下来在十几分钟的可接受时间内,导入了1000万论文数据,最后的详细如下: 1
2
3
4
5
6
7
8节点
Paper: 10000000
Author: 11233099
Org: 3569072
关系
Paper-Author: 25722519
Author-Org: 8368895
Paper-Paper: 3632542
最后折腾来折腾去, 发现我们直接可以对压缩包里面的每一个txt(100万)分别导入,这样就不会crash,只是需要多次导入,不过省了额外的预处理步骤。 这就算一个折腾的记录吧。
总结
初次使用Neo4j, 遇到的坑很多,还有很多问题需要解决,比如直接导入全部边会crash, 即使使用batch(猜想Neo4j图数据很吃内存); 虽然Neo4j提供了一些批导入工具比如neo4j-admin import等,但是更多是针对csv数据,json的暂时还没有调查到。不过一个经验就是将大数据切成小数据来导入,这样肯定没问题。 因为是刚入门Neo4j, 很多优化细节还没掌握,可能很多方法还有优化的地方,恳请指出。