2018.10.28 更新: docker 安装Neo4j的坑
使用docker安装neo4j,官网文档有误,安装之后启动失败; 官网文档上错误的启动命令:
1 | docker run \ |
错误信息大概是:
1 | Active database: graph.db |
原始是因为在neo4j中的logs 在最近的几个版本中,不能再指向/, 因此不能手动--volumns,去掉那一行即可: 1
2
3
4docker run \
--publish=7474:7474 --publish=7687:7687 \
--volume=$HOME/neo4j/data:/data \
neo4j:3.4
此外,如果修改了主机的端口,比如-p 7574:7474 -p 7787:7687 在主机登录的时候,需要修改一下web界面上的host那一项(bolt://ip:7787),不然登录失败。
近期需要处理图数据,考察后打算使用neo4j, 相比其他一些图数据库,neo4j开源,跨平台,接口友好,文档齐全,完整支持ACID。 首先放一张网上的图片,关系型数据库与图数据库存储网络数据的差异:
初次接触neo4j 踩了不少坑,这里记录一下。
关于如何安装Neo4j和使用web ui进行查询操作就不再赘述。
Cypher基本操作
相比关系型数据库的SQL查询语言,Neo4j的查询语言为Cypher,语法更加友好,更适合图数据做查询操作。首先介绍在图数据里面几个概念:
- 节点(Node): 使用小括号表示
(n)表示n这个节点,同时一般都会赋予节点某个标签(Label), 等同于关系书库里面的表名。比如(n: Person)表示n是一个Person类的节点,当然一个节点可以同时有多个label. - 关系(Relation):关系使用中括号表示
[r:Knows]表示r是Knows这种关系。两个节点的关系用--表示,如果有方向的话,加个箭头即可。如(a)-[r:Knowns]->(b)表示节点a和b之间有r关系,其中Knowns为r的类型 - 属性(Property): 节点和关系都可以附带属性,这个也是图数据库的优势,储存属性非常方便,直接用key-value表示即可。比如
(n:Person{name:"John"})表示name为John的节点n。同样关系也可以有属性:[r:Knows]{year: 2018}表示为r赋予一个year属性。
几个常用的关键字介绍:
- MATCH: 表示查询,是读数据库操作。比如查属于Person的节点:
MATCH (n:Person),查找姓名为"John"的节点:MATCH (n:Person){name: "John"}或者使用where语句:MATCH (n:Person) WHERE n.name="John"。当然这里面很多语法可以使用,比如正则匹配等,这里就不再赘述了。当然在实际使用中,MATCH不能单独使用,需要结合RETURN。 - CREATE: 表示创建,可以新增节点,关系,索引,约束等等,是一种写操作。比如
CREATE (n:Person{name:"Ana"})表示创建一个name为"Ana"的Person节点。在创建的同时可以设置属性:CREATE (n:Person{name:"Ana"}) set n.age=20。同样在某个属性上创建索引:CREATE INDEX ON :Person(name),这里需要提一下,尽量所有的Label都设置索引或者UNIQUE约束,在后续的读操作比如MATCH会大大提高性能(创建索引可以在导入节点之前执行)。 - DELETE: 表示删除节点,关系等,也是写操作。一般需要结合
MATCH匹配查询要删除的节点。MATCH (n:Person) DELETE n。如果在删除有关系的节点,这样删除会报错,可以先删除边MATCH (n:Person)-[r:KNOWS]->() DELETE r再删除节点。不过更推荐使用DETACH DELETE来级联删除,MATCH (n:Person) DETACH DELETE n可以同时删除节点及节点的关系。 - MERGE:合并节点或者关系,属于先读后写操作,相当于
MATCH + CREATE,先检查数据库中节点/关系是否存在,如果存在的话就不再创建,反之执行CREATE。如:MERGE(a:Person{name:"John"}) on create set a.age=20 //创建节点,先检测是否存在 // 给节点a,b建立关系,如果a,b已经存在,就无需新建。 MATCH (a:Person{name:"John"}), (b:Person{name:"Ana"}) MERGE (a)-[:KNOWS]->(b)
这几个只是最基本的操作,在复杂查询中,会用到诸如WITH, UNWIND等命令。这里不再详细描述。
几个注意事项:
- 节点名称与节点Label的定义容易混乱。比如
CREATE (n:Person)创建了一个属于Person的节点n。这里的n仅仅属于一个变量名,跟节点本身没有关系,命令执行结束,n的生命周期也就结束了,而Person则是节点本身的Label,会一直存在。 - 索引一定要建立
关于Neo4j浏览器的初次使用有几个快捷键:
- 默认单行输入,按回车执行命令
- 输入一行命令之后,按
SHIFT + ENTER进入多行输入状态 - 在多行输入时,
CTRL + ENTER执行命令 ESC可以放大输入框至屏幕大小,复杂查询的时候,很方便。
关于内存配置的几个参数内存配置:
dbms.memory.heap.initial_sizedbms.memory.heap.max_sizedbms.memory.pagecache.size可以使用neo4j-admin memrec来根据当前数据库数据,查看推荐的内存配置
1 | bin/neo4j-admin memrec --database=graph.db |
导入数据
这一部分主要记录下如何将图数据从文件中导入库,常见的格式为CSV和JSON格式。
导入CSV 格式数据
Neo4j内置了命令来导入CSV数据:使用方法也很简单。假设CSV格式如下:
1 | "Id","Name","Year" |
直接使用如下命令导入并直接引用headers来表示属性并创建节点:
1 | LOAD CSV WITH HEADERS FROM 'FILE:/artists.csv' AS line |
注意事项:
- 分隔符默认是
,, 可以用FIELDTERMINATOR自定义分隔符:LOAD CSV WITH HEADERS FROM 'FILE:/artists.csv' AS line FIELDTERMINATOR ";" - 文件位置: 可以直接使用URL地址作为文件位置,如果是本地文件的话,直接使用"FILE:"表明,文件的位置是相对位置,在配置文件
neo4j.conf中的dbms.directories.import参数可以指定,默认是neo4j安装目录下的import文件夹,将CSV文件放到该目录下即可。 - 对于大规模数据,如果一次性导入可能会超内存,此时可以用
PERIODIC COMMIT来分批提交导入数据,默认是1000行提交一次,具体如下:
1 | USING PERIODIC COMMIT 500 |
- 文本内容存在
"的字段需要特殊处理
导入JSON格式数据
图数据里面更常见的则是JSON数据, 假设数据格式如下:
1 | [ |
列表中每一个map都代表一个User, 其属性有id,name,age; 同时friends字段表示朋友关系,book字段表示读过某本书。 现在我们需要创建 Person 和 Book两类节点,同时Person和Book 之间有READ关系。 Neo4j 并没有内置直接导入Json的函数,不过在Neo3.3版本之后,推出了一个函数存储包APOC,里面包含了非常丰富的函数和存储过程,如各种图计算算法,是Cypher的有力补充,其中就包含了从Json中导入数据。安装APOC很简单,只需要三步:
- 从github中下载与Neo4j对应版本的APOCjar包
- 将jar包拷贝到neo4j安装目录的plugins目录下
- 在配置文件neo4j.conf中加入一行允许APOC导入文件:apoc.import.file.enabled=true
- 重启Neo4j即可
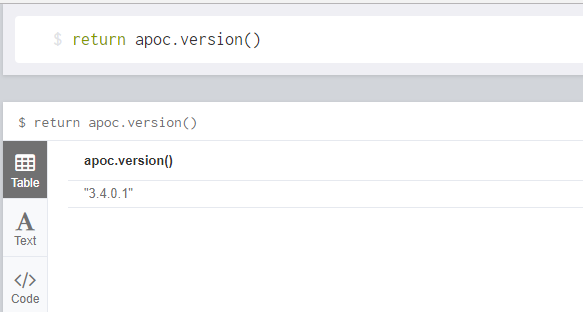
在Neo4j浏览器中,输入return apoc.version()即可查看版本号
此外我们可以看到apoc支持导入非常多格式的数据:

导入方式很简单,我们要创建两类节点,首先创建索引,方便后续导入。
1 | CREATE INDEX ON :Person(id) |
导入代码如下:
1 | // YIELD关键字表示每次导入json数据中的一组数据,即`[...]`中的每一个`{}`, 这里的person.json是系统绝对路径 |
然后再根据已有的friends导入Friend关系:
1 | //对每一个 person遍历 |
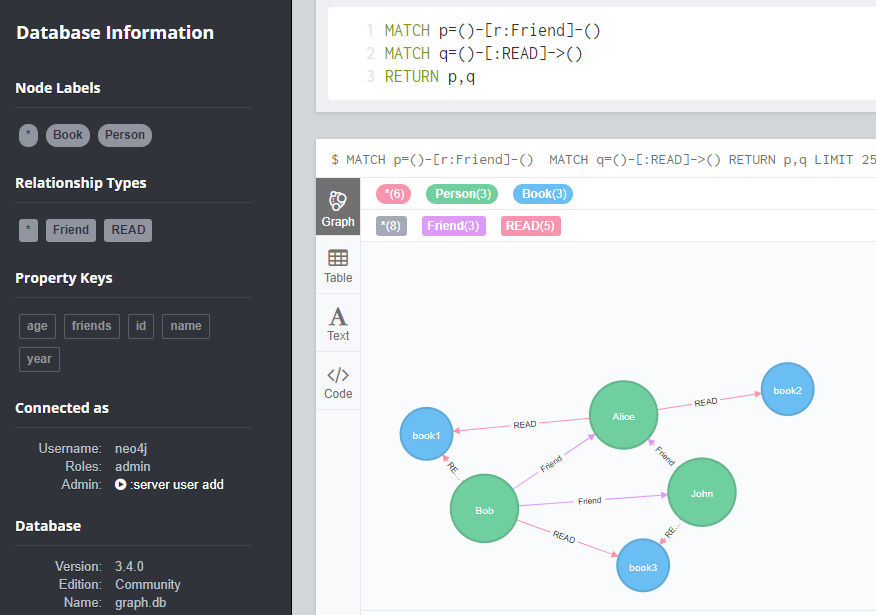
执行按成之后,可视化看一下 ,:
到这里导入基本完成了,不过还有一点问题,暂时没有解决,使用UNWIND person.book as book的时候,如果某个节点没有book这个一个属性,那么后续代码将不再执行,即该Person节点不会创建。但是如果将UNWIND放到创建Person之后,建立的READ关系会有问题,还在查找原因。