近期打算分享一些论文笔记,先从社区问答开始吧
论文信息

问题简介
本文拟解决的问题为社区问答(Community Question Answering), 或者叫Expert Finding。虽然名字中带有QA,但是跟NLP中的问答系统不一样,CQA是在一些问答社区网站上比如Stackoverflow, 知乎等上面,把用户提出的问题推荐给潜在熟悉该问题的回答者(answerer),从而能够使得用户快速地获得更专业的答案。
拿知乎举个例子,如下图:
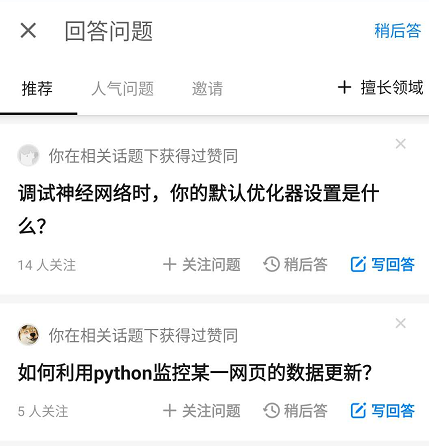
知乎会给用户推荐一些相关问题去回答,逛知乎的同学应该很了解。因此CQA问题本质上就是一个question与answerer的匹配问题,为问题寻找回答者。
挑战与动机
之前大多数CQA的工作均基于文本内容相关性,即将问题与回答者回答过的历史问题集合进行相似度进行简单匹配,但是这样的方法存在一个弊端,即当一个回答者的回答过的问题与提问的问题没有直接显式联系,却包含隐式相关性,那么当前已有的模型就无法做出很好的推荐。
比如下图中Yahoo! Answer的例子:

提问者的问题是关于如何写一篇学术论文,下面的一个候选用户并没有直接回答过类似写论文的问题。 然而从该用户的历史回答问题集合中可以看出该用户其实在撰写学术论文方面还是有足够的专业知识的,因此是有能力回答该问题的。
因此已有的CQA的工作仅仅从单纯文本的表层相似度匹配上来看,很难将该问题推送给上面的用户,这里面需要模型有一定的Reasoning能力,能够挖掘问题与用户历史记录之间的深度关联。
方法
为了解决上面的挑战,本文受到MAC(Memory, Attention, Control)门控机制的启发, 设计了一种推理记忆单元RMC(Reasoning Memory Cells) 来从建模问题文本,进而与候选用户的历史回答进行多方面推理,能够挖掘问题与用户的深度联系。
首先给出CQA的形式化表示:
- 提问的问题q,即:包含多个单词的句子\(q=\{qw_1, qw_2, ..qw_{n_q}\}\) 其中\(n_q\) 是问题的长度。
- 候选用户的历史回答记录集合\(H=[H_1, H_2, ..., H_{n_H}]\) 其中每个回答也是一个包含多个单词的句子: \(H_j = \{hw_1^j, hw_2^j, ..., hw^j_{n_h}\}\)。
- 根据问题q和候选用户的历史回答记录H,判断该用户是否适合回答当前问题。
整体流程如下:
- 使用BiGRU建模question文本Q以及用户的历史回答问题的文本集H,其中word embedding 部分还是结合了subword-level和character-level 的emebdding。
- 利用RMC(Reasoning Memory Cell) 来计算Q与H的各种交互,选出H中与Q更相关的部分
- 控制单元(Control Unit): 这部分主要是挖掘question的不同方面,用来与回答者的问题集合在读入单元与写入单元中进行交互。
- 读入单元(Read Unit): 主要是提取H的相关信息,这里使用Gumbel-softmax 对集合进行了离散化,获得one-hot向量,能够point重要的相关回答。
- 写入单元(Write Unit):更新memory,可以理解为交互层(问题与用户回答的问题集合中重要的部分)。
- 预测模块:作为二分类问题, 根据学到的问题表示以及用户候选集合表示进行01预测,类似CTR
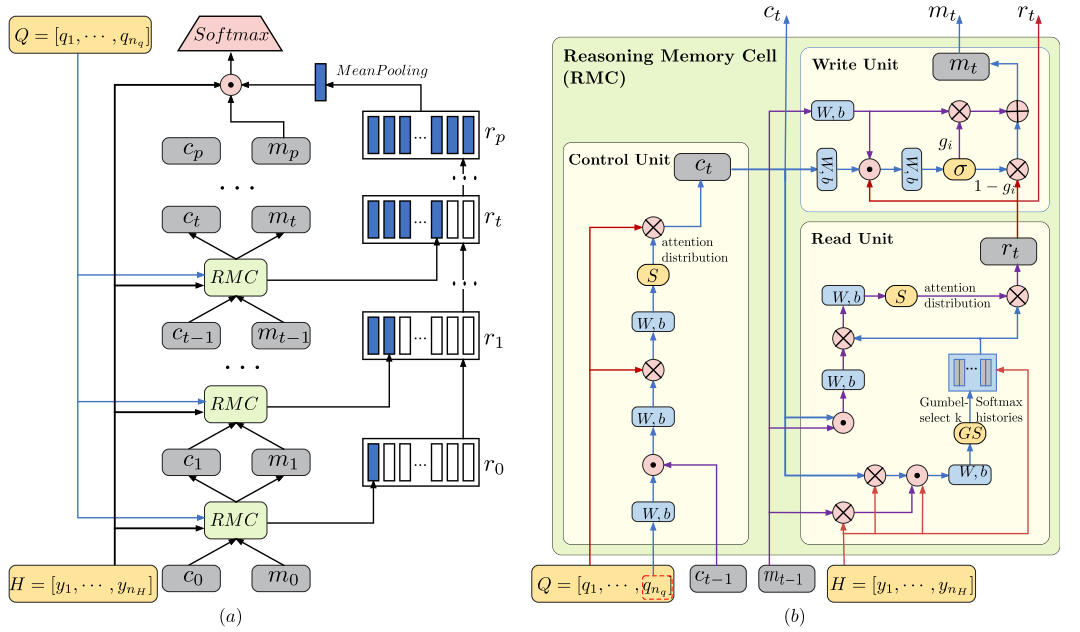
下面具体展开介绍,原文框架图如下:
编码层
- word embedding: 对q与H中的所有的词,均使用多粒度的word embedding技术来缓解OOV的问题,毕竟社区问答语料口语化比较严重。将每个词的
word-level,subword-level和character-level进行concatenate作为word最终的特征表示: \(e_j = [e^w_j; e^s_j; e^c_j]\) 其中subword使用BPE进行编码,character-level直接使用ELMo的预训练词向量。 - 使用Bi-GRU对问题q进行编码:\(Q=[q_1, q_2, ..., q_{n_q}]\) 其中\(q_i=BiGRU(qw_i)\),需要说明的这里面的\(q_i\) 是一维向量,表示问题中第i个词的特征,\(Q \in R^{q_{n_q} \times d}\) 其中d为BiGRU的输出维度。
- 使用Bi-GRU对候选用户的问题集合H进行编码: \(y_j=BiGRU(H_j)\), \(H=[y_1, y_2, ..., y_j, ..., y_{n_{H}}]\)。 其中\(y_j\)表示第j条回答记录的表示,这里需要注意的是,此处做了pooling操作,保留的是sentence-level的特征,因此\(y_j\)是一个向量,而不是词特征矩阵,因此\(H\in R^{n_{H} \times d}\),\(n_H\) 为候选用户的历史回答问题数目。
后续的RMCs的输入就是 \(Q\) 与 \(H\) , 学习二者的交互。
RMCs 推理记忆单元
类似RNN/GRU/LSTM等,包含基本cell,然后进行多步循环。 其中每个基本单元RMC包含三个unit,分别是control unit,read unit与write unit,三个变量分别是控制向量\(c\),记忆向量\(m\), 以及状态输出向量\(r\) 。
1.Control Unit 。 从图中可以看出来,输入是Q和上一时刻的控制向量\(c_{i-1}\), 使用多个MLP层,选出Q中当前重要的词,进一步更新下一时刻的控制向量\(c_i\)(这部分的符号的下标均指的是第时刻,或者迭代)。
首先将Q中最后一个词的隐状态向量\(q_{n_q}\)作为句子的初始表示,之后通过一个MLP层进行线性转化,然后串联\(c_{i-1}\):
\[ q_i = W_i{q_{n_q}} + b_i \\ cq_i = W_{cq}[q_i,c_{i-1}]+b_{cq} \]
后面开始计算词分布:
\[ \alpha_i = softmax(W_\alpha(cq_i\otimes Q)+b_{\alpha}) \\ c_i = \sum_{j=1}^{n_q} \alpha_i Q \]
其中\(cq_i \otimes Q\) 表示向量与矩阵的列进行element-wise product,得到一个新的矩阵。\(w_\alpha\in R^{d*1}\), \(\alpha_i \in R^{n_q}\)表示问题中\(n_q\)个词的权重系数, 最后与Q中对应词的特征加权求和,得到第\(i\)时刻的控制向量\(c_i \in R^{d}\)。
其实本质上就是一个Attention的过程,其中\(c_{i-1}\)是查询向量,计算Q中词的important weight分布,只是文中计算方法相对复杂一些,按说可以直接用 dot-product能达到类似效果,这样\(c_i\) 中就可以捕获到当前时刻应该关注问题中哪些词。
2.Read Unit 。这部分主要是来衡量候选用户的历史记录中, 哪些记录与当前问题更加相关,其实类似从H中retrieve有用的信息。输入就是根据控制向量\(c_i\) ,上一时刻的记忆向量\(m_i\)与 历史记录集合\(H\)。
首先使用MLP计算H与\(c_i\)和\(m_{i-1}\)的交互特征矩阵:
\[ mr_i = H \otimes m_{i-1} \\ cr_i = H \otimes c_{i} \]
得到的\(mr_i\) 与 \(cr_i\)均是与H同维度的矩阵,之后在使用Attention机制,来计算H中历史回答的weight,直接使用MLP的计算方法:\(\pi_{i} = W_e[mr_i, cr_i, H]+b_e\), 其中\(w_e \in R^{3d*1}\), 因此最终得到候选用户的历史回答问题记录的score: \(\pi_{i} \in R^{n_{H} * 1}\)。
这里需要注意的是后面并没有使用softmax 来score 求归一化后的weight,而是使用Gumbel-softmax 来得到one-hot的离散化的weight。这样做的目的是为了能够找出在当前时刻,某一个历史记录与当前问题最相关,直接将该历史记录拿出来进行后续计算。但是一次Gumbel-softmax只能point 一个相关的历史记录,因此一般情况,都会执行多次Gumbel-Softmax (应该是多组计算weight的MLP参数),这样可以得到多个历史记录,如下:\(\tilde{H}^i = [\tilde{y_1}^i, \tilde{y_2}^2,...., \tilde{y_k}]\)
其中,k表示执行次数,\(\tilde{y}^i_j\)表示在当前i时刻, 第j次Gumbel-softmax所挑出的那个历史记录的表示向量。 这里类似self-attention中的multi-head。
之后再利用一个Attention机制,利用\(m_{i-1}\)和\(c_i\)作为query vectors, 来对这k个选出的历史记录做一个re-weight如下:
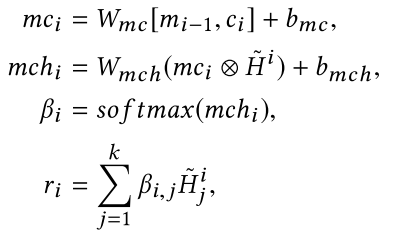
这样得到的向量\(r_i\)包含了在当前控制向量与记忆向量参与下,候选用户的历史记录信息最相关的部分, 为了将前面时刻的信息包含进来,这里又做了一种类似残差的操作, 经过p个step之后,最后的信息将所有的r聚合起来: \(R=[r_1, r_2, ..., r_i, ...,r_p]\)。 这里的\(R\) 就可以作为候选用户的表示了。
3.Write Unit 这部分自然就是更新记忆向量\(m_i\)了, 利用\(m_{i-1},c_i, r_i\)各自几个MLP进行融合,最后利用一个简单的gate门控,来判断保留多少旧信息,和新加入多少新信息: \(m_i = g_im_{i_1}+(1-g_i)r_i\)。
这样整个RMC就完成了一次更新。 很多细节的内容,不过回头看,本质上,control unit与 read unit 就是两个Attention模块,其中control unit的attention为了选出当前应该关注问题中的哪些词,read unit中的attention则是为了找出候选用户的历史记录中哪些与问题更相关。 而memory则代表一种全局信息,可以连接\(c_i\)和\(r_i\)。 这是本文计算Attention的方法比较复杂,使用了非常多的MLP。
预测模块
这部分额就是预测候选用户是否会回答这个问题,作为二分类问题,最后的特征向量,包含memory信息\(m_i\),问题向量\(q_{n_q}\)和RMC的输出用户向量\(\hat{r}=MEAN(R)\), 直接将所有step的r取平均作为最终的候选用户的特征。
继续使用MLP计算预测logits: \(f=W_f[m_i, q_{n_q}, \hat{r}] + b_r\)。模型使用cross-entropy 来训练。
实验
本文使用两个CQA数据集如下:
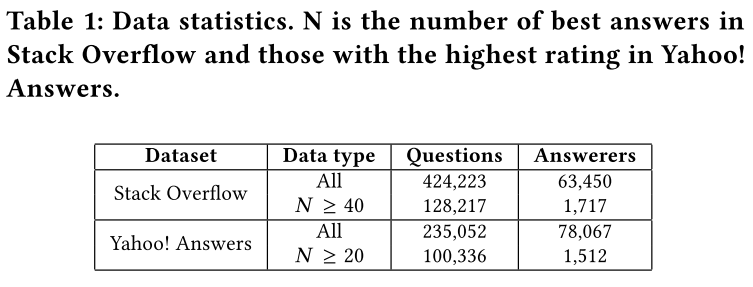
在CQA中模型可以给出一个候选用户list,因此实验使用S@N (Successfule@N) 也就是recall@N作为评价指标,即预测出的TopN中出现了best answerer 即可。
首先看与baselines的对比实验结果,前面提到文中使用了多种的word embedding, 因此根据使用的Embedding类型,设置了四种模型,其中基本模型为RMRN,表示仅仅使用了word embedding. 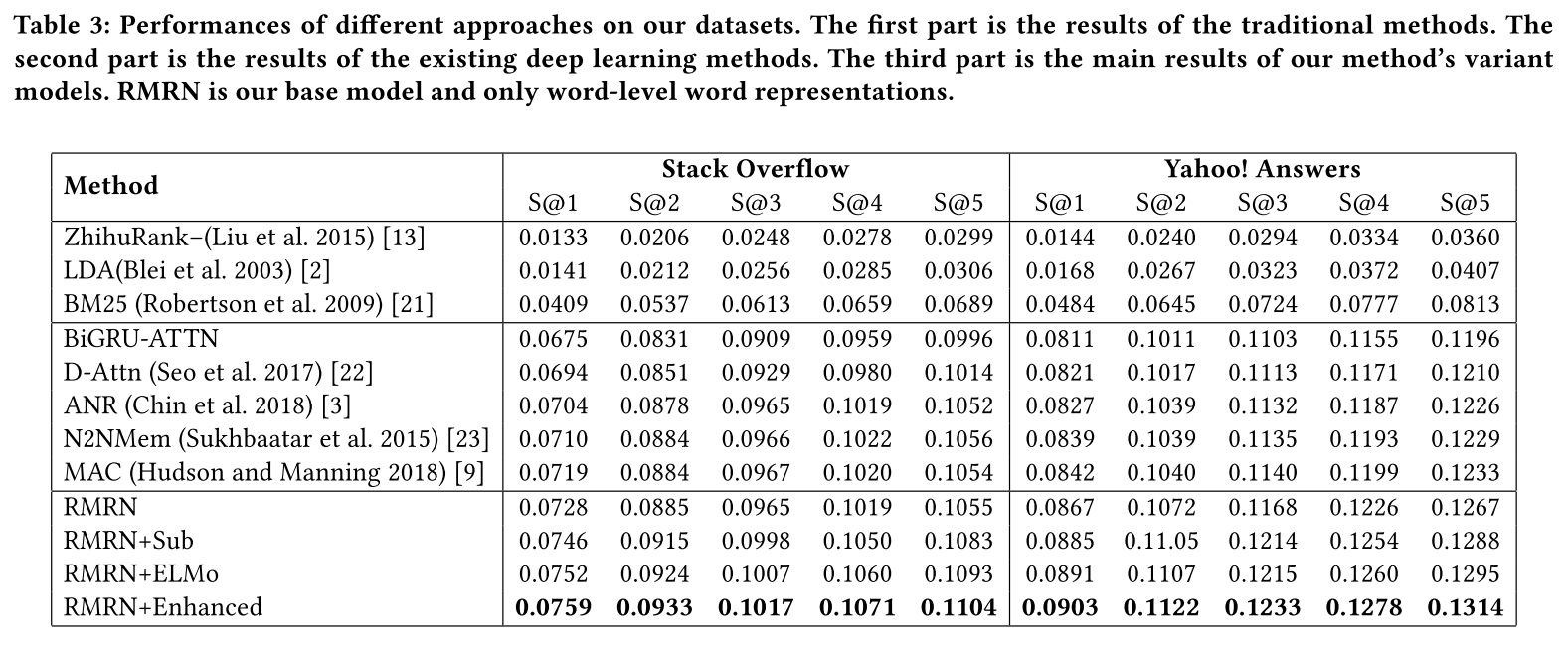
从实验结果可以看出来:
- 标准的RMRN在一些数据集上无法取得最优结果,或者与baseline差距非常小。
- 加上多粒度的word embedding的RMRN+sub/ELMo/Enhanced 效果就明显提高, 这个说明了模型的基本输入很重要,原因应该是在CQA语料中,非常多的口语化用语或者专业用语,导致OOV现象严重。 另一方面也说明模型本身效果或许不是十分优越。
另外一个有意思的消融实验结果如下:
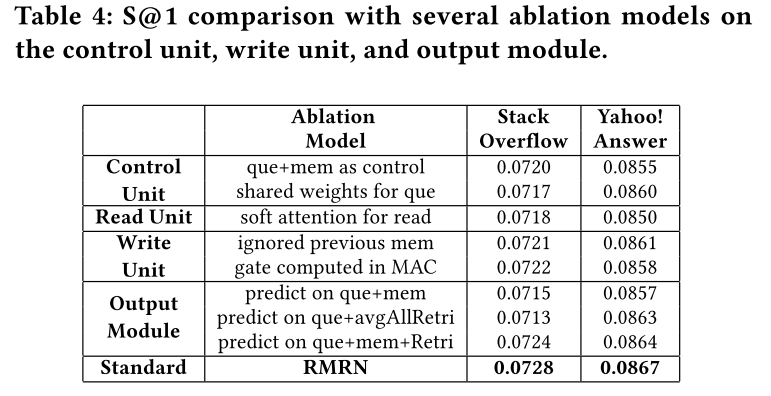
主要对control unit, read unit和 write unit以及predict 部分进行了ablation study
从实验中可以看出:
- 每个模块对模型的性能都有一定影响。
- 对模型影响最大的还是预测层使用特征,三类特征都对模型有用。
- read unit中的Gumbel-softmax的作用也很明显,换成softmax attention效果下降较多。
总结
这篇文章使用的RMC模块能够在一定程度上刻画问题与候选用户的深度联系。RMC的每个Step中,control unit可以学习到问题中的一个词重要性分布,read unit 可以根据当前的词重要分布,学习(Reasoning)出候选用户的哪些历史回答更相关。write unit 更新全局信息。 这样多个step进行recurrent,模型就可以学到更多的关联信息。本文的模型描述非常详细,完全可以根据模型复现。 此外,本文使用多粒度的词特征,缓解OOV的问题,实验证明效果得到了显著提升。不过稍显不足的是,作为核心的RMC带来的效果提升并没有那么明显,另一方面就是缺少Case Study,来直观的表明RMC的几个地方,是否匹配到了真正相关的词和历史记录,不同step是否有递进的reasoning能力。