接前面笔记:关系抽取总结中最后说的,在关系抽取基于Distant Supervision的NYT+Freebase的数据集有两个版本,目前大部分文章都是在这两份数据集上做的。通过纵向实验发现,同一个模型在不同版本数据集上的表现有不少差异,这篇笔记是基于自己使用Pytorch复现的PCNN(Zeng 2015)与PCNN+ATT(Lin 2016)的实验结果来简单对比。
代码地址: pytorch-relation-extraction,关于实现的细节,调参,踩过的一些坑等,会记录在readme中,这里不再赘述。
个人属于入门级别, 复现代码可能有问题, 结果供参考.
数据集
首先描述一下这两份数据集:
27类关系,Zeng2015 发布的数据集,做了一些过滤,如删除了两个实体之间距离大于40个词的句子,以及去掉了实例少的关系,相对较小,以SMALL表示:详细数据如下所示: 训练数据集:
- 实体对: 65726; 句子数: 112941; 关系数: 27
- 实体对: 93574; 句子数: 152416
53类关系,Lin2016 发布的数据集,没有做过滤,相对较大,训练数据大概是小数据的4倍,以LARGE表示,详细如下: 训练数据集:
- 实体对: 281270; 句子数: 522611; 关系数: 53
- 实体对: 96678; 句子数: 172448;
下面分数据集分别看这两种模型的效果,目的有两个: (1) 验证自己复现的模型是否达到了论文模型的效果。(2) 比较模型在不同数据集上的效果。
此外如果读过两篇论文的代码的话,可以看出关于最后的Evaluation的步骤是有所差异的:
- 在Zeng 2015 中,直接遍历所有的测试数据集的实体对,然后预测其关系,接着按照预测的概率从大到小排序,忽略那些标签为NA并且预测为NA的样例,因为这部分没有意义且数据量巨大,这样保存好precision和recall,来绘制PR曲线。
- 在Lin2016中,则是取了预测概率Top N (N=2000+) 的样例,然后同样忽略了NA的情况,然后用这部分数据来绘制PR曲线。
总体来说:这两种方法很类似,因为在绘制PR曲线的时候,最后有一个截断,本质相同。
实验结果
LARGE数据集
直接上跑的结果, PR曲线: 
其中:
- PCNN+ATT: Lin2016 论文中给出的结果,直接拿来用
- PCNN+ONE+MY: 自己复现的Zeng 2015的模型
- PCNN+ATT+MY: 自己复现的Lin 2016的模型
当时看到结果的时候,很惊讶:
- PCNN+ATT+MY 的PR曲线略高于Lin2016的PCNN+ATT,这个结果说明复现的模型基本吻合原模型,可能因为一些框架不同,优化上的因素导致效果更好。
- PCNN+ONE+My的 PR曲线基本与Lin 2016的PCNN+ATT 持平,有的位置还要高一些。 这个就有点不太理解了。
- PCNN+ONE+My 与 PCNN+ATT+MY 并没有想象中的差距那么多, 这个也很有意思,说明Attention 没有起到很大的作用?
SMALL数据集
PR曲线的结果: 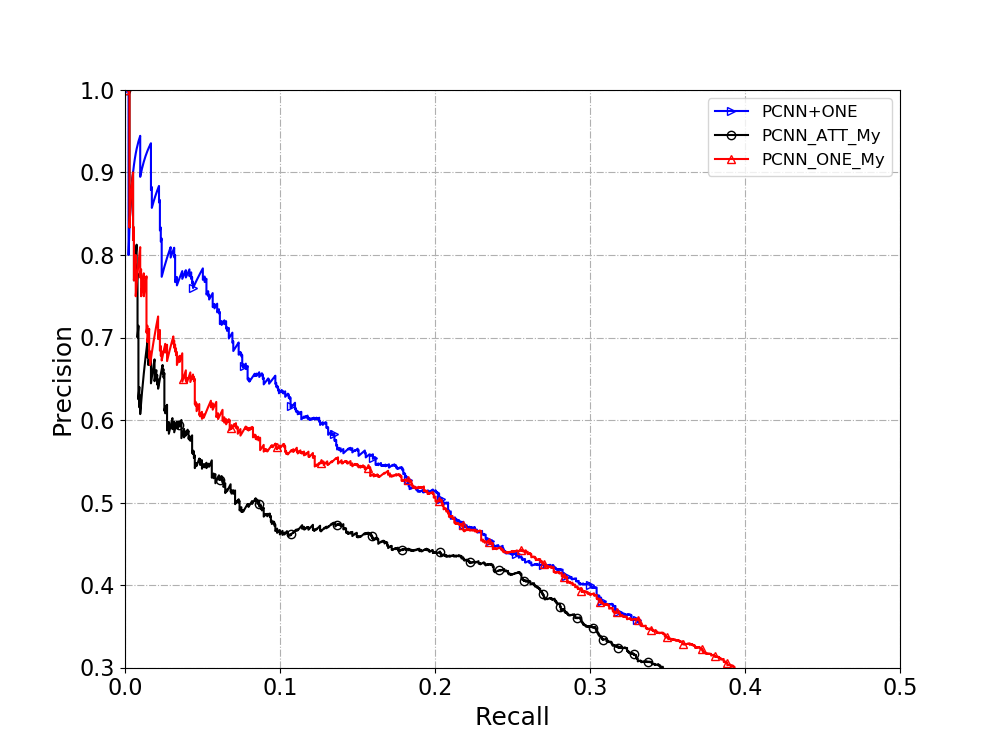
结果:
- 测了很多参数,自己实现的PCNN+ONE 在recall比较小的时候,达不到Zeng2015使用Theano实现的模型效果, 原因还会继续查找。在recall相对较大的时候,基本可以达到Zeng2015的效果。
- 自己实现的PCNN+ATT 在SMALL数据集上效果一般, 很差异的是, ATT与PCNN+ONE的效果差很多. 复现基本上是参考C++代码来写的,还有调参数等.
总结
- 大部分模型在LARGE数据集上效果要比SMALL数据集要好,可能原因是LARGE训练数据量大,因此模型可以训练得更好。
- 从个人实现结果来看,对于减弱Distant Supervision的噪音来看,在LARGE数据集上,Attention的效果与Multi Instance(仅仅去最可能正确的instance) 基本差不多, 但是在SMALL数据集上,Attention的效果并没有Multi Instance 的好。
当然这个是我个人的实验结果(另外一师弟实现的结果与此类似), 后续如有可能的话, 会补充一下在Lin2016的C++源码上跑一下SMALL数据集,以及在Zeng2015的Theano数据集上跑一下LARGE数据集,最终的结果会更有说服力。个人复现难免会有遗漏,如果错误,烦请指出.