2018.10.14更新: 增加全监督关系抽取PCNN的复现代码: PCNN.
2018.07.08更新: 增加对远程监督两份数据集补充实验对比: 关系抽取实验.
2018.04.04更新:增加对NYT+Freebase数据集的两个版本的说明
对近几年(到2017)一些关系抽取/分类(Relation Extraction)的部分文献的一个简单总结。
基本介绍
基本定义
- 关系抽取: 从一个句子中判断两个entity是否有关系,一般是一个二分类问题,指定某种关系
- 关系分类: 一般是判断一个句子中 两个entity是哪种关系,属于多分类问题。
常用数据集
- ACE 2005: 599 docs. 7 types;
- SemiEval 2010 Task8 Dataset:
- 19 types
- train data: 8000
- test data: 2717
- NYT+FreeBase 通过Distant Supervised method 提取,里面会有噪音数据:
- 53 types
- train data: 522611 sentences; 需要注意的是,这里面有近80%的句子的标签为NA
- test data: 172448 sentences;
下面以学习方法的不同来对这些文章进行分类:
- Fully Supervised Learning
- Distant Supervised Learning
- Joint Learning with entity and relation
- Tree Based Methods
其中Fully Supervised 一般评测使用label完全准确的SemEval 2010 Task 8 数据集。 Distant Supervised 使用NYT+FreeBase数据集。 SemEval 2010 Task 8 训练数据样例: 1
2
3 The <e1>microphone</e1> converts sound into an electrical <e2>signal</e2>.
Cause-Effect(e1,e2)
Comment:1
m.0ccvx m.05gf08 queens belle_harbor /location/location/contains .....officials yesterday to reopen their investigation into the fatal crash of a passenger jet in belle_harbor , queens...... ###END###
这两个数据集相对来说用的最广泛。关于Distant Supervision的NYT+Freebase数据集有两个版本,会在文末说明。 此外关于Joint Learning with entity and relation和Linguistics(NER, POS Tagging, Dependency Tree) Methods 部分暂时还没有关注,仅仅列在这里。
Fully Supervised Learning
相关文献
这一部分基本是在SemEval 2010 Task 8 数据集上做关系分类的工作,是一个完全监督的任务。
1. Simple CNN Model (Liu 2013)
Liu,(2013). Convolution neural network for relation extraction. 8347 LNAI(PART 2), 231–242.
基本介绍 这篇文章应该是第一次使用CNN来做关系分类任务的,使用的CNN结构也十分简单,甚至没有Pooling层,输入层也没有用word embedding, 而是对synonym的embedding表示作为输入。 具体的输入层的结构如下:
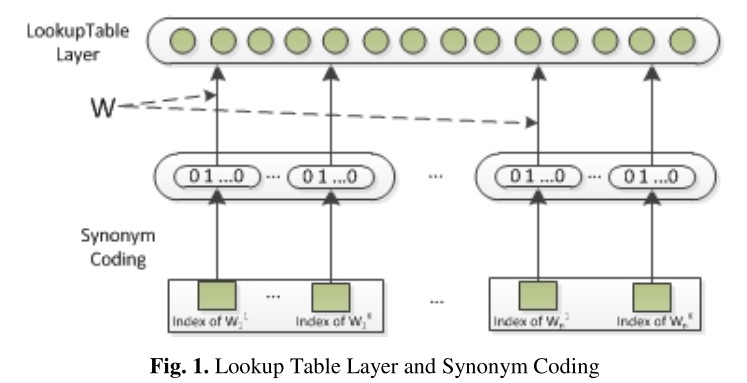
具体步骤如下:
- 首先构建synonym list,使用Wordnet数据集,来找那些词属于同义词,相当于利用同义词关系,聚成若干类,当然有可能会有某个词没有同义词,那他自己就是一个类别
假设Synonym list 一共有\(D_s\)个类别,每个词都属于其中一类,这样就可以来对词做one-hot表示了, 如上图所示:
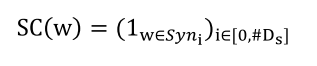
使用一个Look-Up Table 转换为一个低维vector
输入层之后是卷积网络+一个普通的全连接层以及softmax分类,如下: 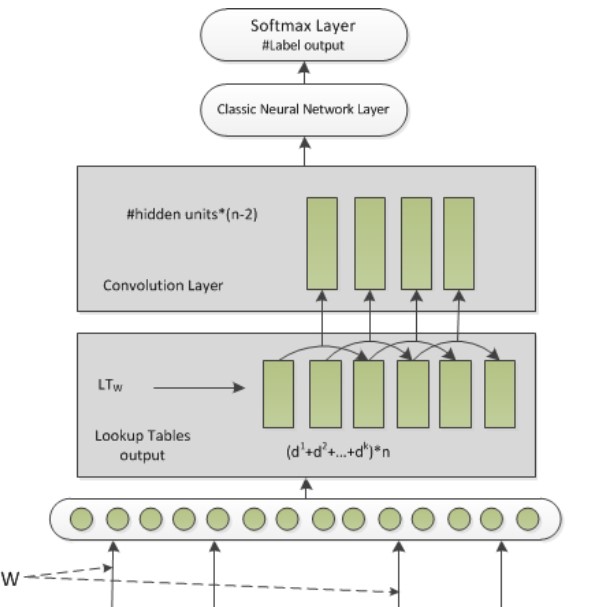
实验
数据集: ACE 2005数据集 这里需要说明的是, 这篇文章除了使用前面说的Synonym的特征之外,还用了该数据集提供的entity type/subtype 以及后续做了POS tagger 的特征,都是先使用one-hot表示,然后用LookUP Table 再转换为低维向量,然后所有的feature vector concat成最终的向量,作为CNN层的输入。 在大类Type上的实验结果,相对于几个Basedline 提升还是比较明显的:

总结
优点:
- 引入CNN 结构来做关系抽取,虽然本质上属于文本分类,但是属于一次尝试,效果还可以。
- 使用Synonym Embedding作为词的特征,这一点后续一部分工作也在使用,相当于引入额外的信息。
缺点:
- CNN的结构比较简单, 没有Pooling层,可能受噪音比较明显,因为一个句子里面影响两个词的relation的可能只有几个词,一些可能会产生噪音。
- 仍然使用了一些Linguistic Feature比如POS Tagger, NER 等,并没有完全做到end-to-end的关系抽取
- 使用Synonym Embedding(随机初始化的LookUp Table) 可以引入一部分额外信息,但是却完全忽略了word embedding的语义信息,这一块在后续工作中都会加入pre-train的word embedding.
2. CNN with Max Pooling and word embedding(Zeng 2014)
Zeng, . (2014). Relation Classification via Convolutional Deep Neural Network. Coling, 2335–2344
这篇是中科院刘康老师的一篇文章,这篇文章使用了比较经典的CNN的结构,包含了Pooling层,以及设计了Position Features,后面会具体介绍。 先看整体架构:
- 第一步同样是Embedding Layer, 这篇文章用了Pre-Train的词向量,而不是像上一篇的随机初始化,不过用的并不是word2vec,而是(Turian 2010ACL Word representations: a simple and general method for semi-supervised learning.)提供的word embedding.
- 之后文中设计了两种Features: Lexical Level Feature 就是词法级别,以及sentence-level(CNN) 级别的特征,后面详细介绍。
- 将两种Feature 直接 concat 输入到一个全连接层+Softmax 来对关系做分类
先介绍相对简单的Lexical-Feature,一共有5部分:
- L1: entity1
- L2: entity2
- L3: entity1的左右两个tokens
- L4: entity2的左右两个tokens
- L5: WordNet中两个entity的上位词
举个例子,比如说:
The [haft] of the [axe] is made of yew wood.
- L1: entity1: haft
- L2: entity2: axe
- L3: entity1's context: the, of
- L4: entity2's context: the, is
- L5: 在wordNet中找到两个entity的上位词。上位词就是包含关系,比如parrot这个词的上位词就是bird. 这种包含关系其实类似于指明了实体的类型特征。
这5个特征都是lexical-level的,之后在使用它们的word embedding串联起来 作为最后的lexical-feature.
下面介绍使用CNN的sentence-level feature, 跟其他文章中使用CNN对句子建模的结构很类似, 先直接放框架图:
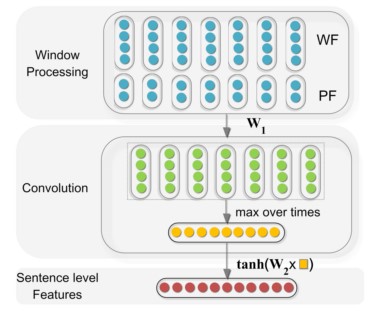
在输入层每个word 有两种特征:
- WF(word feature): 很简单就是词向量 word embedding
- PF(position feature): 位置特征, 每个word与两个entity的相对距离,举个例子如下
这个单词距离entity1 为2,距离entity2 为-4:  这样每个word 就有了两个位置特征[d1,d2],这两个特征也需要再额外使用Lookup-Table 做Embedding,投影成低维向量,也就是每个相对距离,都对应到一个低维实数向量。 这个Position Feature 的引入其实是突出了两个entity的作用,实验证明PF对效果的提升很明显。
这样每个word 就有了两个位置特征[d1,d2],这两个特征也需要再额外使用Lookup-Table 做Embedding,投影成低维向量,也就是每个相对距离,都对应到一个低维实数向量。 这个Position Feature 的引入其实是突出了两个entity的作用,实验证明PF对效果的提升很明显。
这样每个word的feature维度为: \(d_w + d_p * 2\),其中\(d_w\) 为word embedding的维度,\(d_p\)为 position embedding的维度。
介绍完输入之后,接下来就是卷积操作,这里不多介绍。与上一篇不一样的地方是,这里在卷积之后使用了Max Pooling操作,这样可以提取每一个卷积核的最有用的特征,在之后又接了一个全连接层最终得到了sentence-level feature。有一点需要说明的是,MAXPooling直接对卷积操作之后的向量进行的,并没有经过激活函数。
最终将上面的lexical-feature 与 sentence-level feature 直接串起来,作为整个句子的特征去做分类,如结构图中所示,加一个全连接层和softmax 即可。
模型需要学习参数有: - word embedding - position embedding - 卷积核权重矩阵 - sentence-level 最后的全连接层参数矩阵 - 用于softmax的全连接层参数矩阵
实验
数据集: 使用SemEval 2010 Task 8 Dataset,考虑方向共19种关系。 整体的实验结果如下:

从结果看,没有使用linguistic的一些特征,基本end-to-end, 取得了state-of-art的效果。 再看看单独特征的影响:
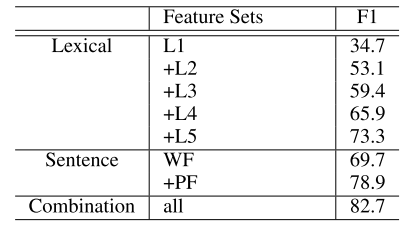
可以看出来,L5(word net)和PF两个特征比较关键。
总结
优点:
- 使用Pooling 操作,提取了每一个卷积核对应的最优特征
- 引入Position Feature: 相当于在一定程度上引入了位置信息,因为CNN更多是局部N-Gram特征; PF突出了entity的影响,包括后续的PieceWise Max Pooling,同样也是对entity与其他词分开考虑。
缺点:
- 虽然使用了多个卷积核,但是仅仅使用同一个window-size, 提取特征比较单一。
- 结构还是相对简单,更多的是类似于CNN 文本分类的结构。 而且还是加入了人为构造的Lexical Feature。
有一点疑问的是 Lexical中的两个entity 的embedding 其实也属于对entity的强调,作用跟Position Feature 感觉有点类似,都是为了突出是对句子中的那两个词做关系分类,或者说都是为了强调距离target entity 越近,影响越大。但是PF的效果要比L1-L4好。
3. CNN with multi-sized window kernels(Nguyen 2015)
Nguyen, (2015). Relation Extraction: Perspective from Convolutional Neural Networks.
这一篇文章,在去年zeng的基础上加入了多尺寸卷积核,这样可以提取更多的N-Gram特征;同时完全不再使用zeng的lexical-level feature,完全使用sentence的特征,完整的结构如下: 
从结构可以看出来,基本与上一篇zeng的sentence-level 部分的CNN很类似,不同的地方有: - 卷积阶段使用多个尺寸的卷积核 - 卷积之后使用了激活函数
实验
数据集:文中使用了ACE 2005 和 SemEval2010 Task 8 两个数据集。 对ACE 2005数据集,做了窗口尺寸不同以及word embedding是否固定的实验分析,结果如下:
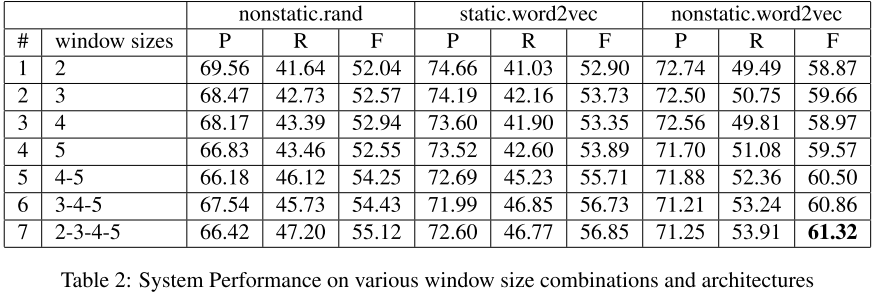
从实验结果F1-Score值可以看出来,多窗口尺寸的确有效果提升,而且最好的效果则是在word embedding 不固定,需要参与训练的情况下,卷积核窗口为2,3,4,5。
在SemEval2010 数据集的结果达到了state-of-art,比zeng的效果好0.1% 但是是不加任何的lexical-feature的情况下:

总结
这篇文章改进相对较少, 不过完全不再使用lexical-feature,起到了不错的效果。 优点:
- 使用多个卷积核,提取文本中更多的卷积特征
- 完全不再使用词法特征,包括wordnet, 词的上下文等。
缺点:
- 仅仅使用CNN的传统结构,因此效果提升不是特别明显
4. CNN with Rank Loss(Santos 2015)
Santos(2015). Classifying Relations by Ranking with Convolutional Neural Networks. ACL
这篇文章同样是在Zeng 2014的CNN基础上做的改进,最大的变化是损失函数,不再使用softmax+cross-entropy的方式,而是margin based的ranking-loss。下面介绍一下细节。 先看整体架构,跟之前的区别很小:
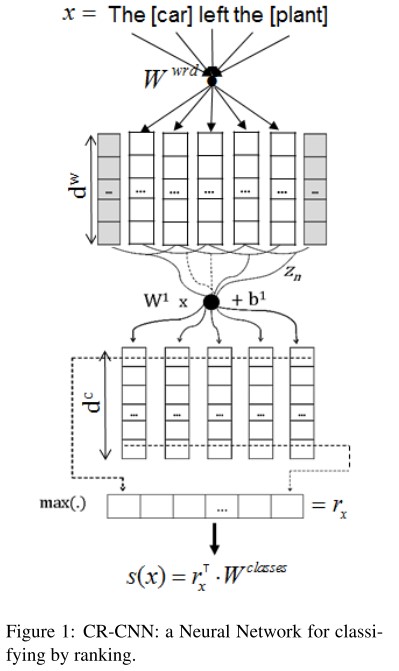
- 输入层: 利用word embedding + position embedding,同zeng 2014
- 卷积层: 固定尺寸的卷积核(window-size=3)
- Pooling层: 直接Max Pooling得到 \(r_x\)
- 全连接层: 得到每个类别的score,其中\(W^{classes}\)的每一列可以看成 label 的embedding。因此某个label为c的score即为: \(s_{\theta}(x)_c=r_x^{T}[W]_c\)
图中pooling之后得到的\(r_x\) 即作为sentence representation。这一部分跟之前的工作都一样,下面开始引入了margin-based ranking loss, 先看loss function:
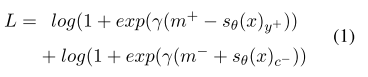
在训练过程中的输入有三部分: 当前的句子 x , 该sen的正确标签\(y^{+}\), 以及采样得到的错误的标签\(c^{-}\)。\(m^{+}, m^{-}\) 对应两个大于0的margin, \(\gamma\)起到了一个缩放的作用。 这样最小化\(L\)就要求正样本对应的label得分\(s_{\theta}(x)_{ {y}_{+} }\)越大越好,负样本对应的得分\(s_{\theta}(x)_{ {c}_{-} }\)越小越好。同时margin的存在使得模型尽可能让正样本的得分大于\(m^{+}\) , 以及负样本的得分小于\(-m^{-}\)。这样可以讲正负样本分的更加清楚。
几个Tips:
- 负样本的选择上, 并不是随机选择一个负标签,而是选择score最大的那个负标签,这样可以更好地将比较类似的两种label分开。
- 关于NA label的特殊处理,NA表示两个entity没有任何关系,属于噪音数据,因此如果将这个噪音类别与其他有意义的类别同等看待的话,会影响模型的性能. 因此文中对NA类做了特殊处理。在train的时候,不再考虑NA这一类别, 对于NA的训练数据,直接让(1)式的第一部分为0即可。 在predict的部分, 如果其他类别的score都是负数,那么就分类为NA。实验证明这个效果对整体的performance有提升。
实验
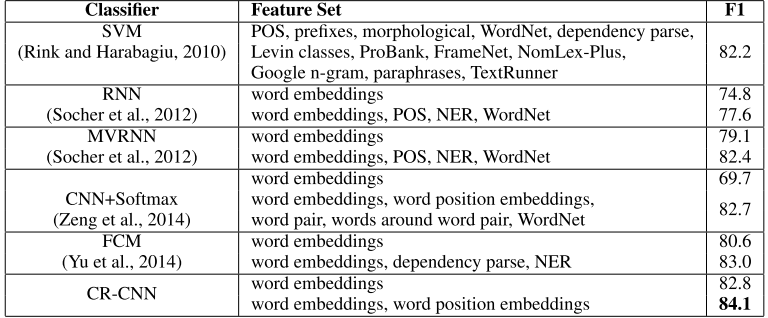
数据集: SemEval2010 Task 8 首先看主要实验结果, 再不使用任何lexical-feature的情况下,达到了start-of-art的效果, F1-Score: 84.1%:
再看三组对比实验: - 损失函数: Ranking Loss 以及 Softmax-Entropy. 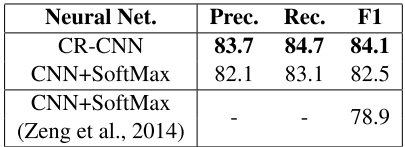 上面的CNN+Softmax 是文中复现的Zeng 2014的代码,比原文中要好,可能原因是本文使用了300维的word embedding, 而Zeng使用50维. 从前两行可以看出来,使用Ranking的损失函数,Precision, Recall, F1 都有提升。 - 对NA关系的特殊处理的效果:
上面的CNN+Softmax 是文中复现的Zeng 2014的代码,比原文中要好,可能原因是本文使用了300维的word embedding, 而Zeng使用50维. 从前两行可以看出来,使用Ranking的损失函数,Precision, Recall, F1 都有提升。 - 对NA关系的特殊处理的效果: 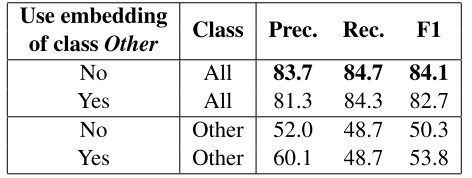
从结果中可以看出来,训练过程中不考虑NA的话,整体的performance有提升。 但是对于NA这一个单独的类的Precision有所下降,也就是说有更多的其他的类分到了NA,导致P降低,不过反过来看其他类的P,R,F1的值都提高了,说明增加的这部分分到NA类的那些case即使在考虑NA的情况下,也是Bad Case.使用两个entity之间的word embedding 来代替position feature:
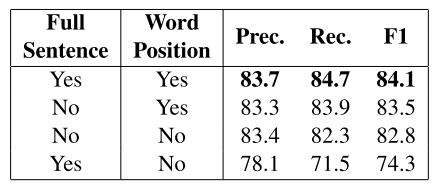
其中Full sentence 表示 使用完整的句子, Word Position表示使用Zeng 2014提出的Positon Embedding。从第一列和第四列的对比可以看出来,在使用Full Sentence的情况下,Postion 的作用很明显,可以差出10%。不过从第二列,第三列对比可以看出来,如果仅仅使用两个entity之间的words,position的影响就会小很多,因为这种情况下,就可以一定程度上指代两个entity的位置。有一个比较有趣的现象,第三列仅仅使用两个entity之间的word, 就可以达到82.8%的F1,已经可以跟Zeng2014 中,使用各种lexical-feature+position feature达到相同的效果。可能的原因是长文本的噪音比较大。
总结
这篇文章相对Zeng 2014的文章,改进的地方或者一些尝试很值得思考。而且效果很不错,很多地方可以借鉴,尤其ranking loss这一块。
优点:
- 使用Ranking loss,效果提升2%多,而且在没有使用lexical-feature以及单窗口尺寸的情况下。 有提升的原因可能是使用ranking loss可以更容易区分开一些易于分错的类别,而softmax却没有这样的功能,只可以增强正确类别的概率。
- 使用仅仅两个entity之间的words 可以在一定程度来替代position的作用,而且实现更简单。
缺点:
- 同样仍然在简单CNN的基础上做的修改. 后续相关文章加了各种attention.
5. RNN (Zhang 2015)
Zhang (2015). Relation classification via recurrent neural network.
这篇文章不再使用CNN作为基本结构,而是开始尝试RNN,可以达到Zeng 2014 的效果,基本结构如下:

大部分结构相同,有以下几点改进:
- 使用双向RNN来处理,捕获更多的信息。
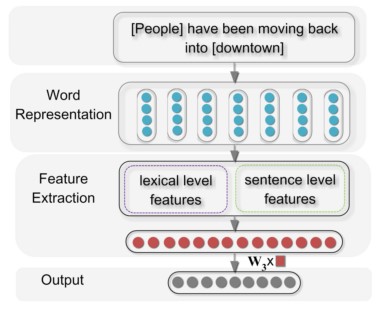
- 使用更加简单的Position Indicators(简称PI),而非Zeng 2014的Position Feature. PI很简单,直接使用
标签来表示两个entity的位置. 比如在数据中例子: “ people have been mov- ing back intodowntown ” 这样就将<e1>, <\e1>, <e2>, <\e2>作为四个Indicators. 在训练的时候,直接将这四个标签作为普通的word即可,无需特殊处理. 通过这样的方式来突出两个entity.
实验
数据集: SemEval 2010 Task 8 首先是一个简单的特征对比实验:

可以看出来PI这个特征也可以取得不错的效果。 下面是模型对比实验:
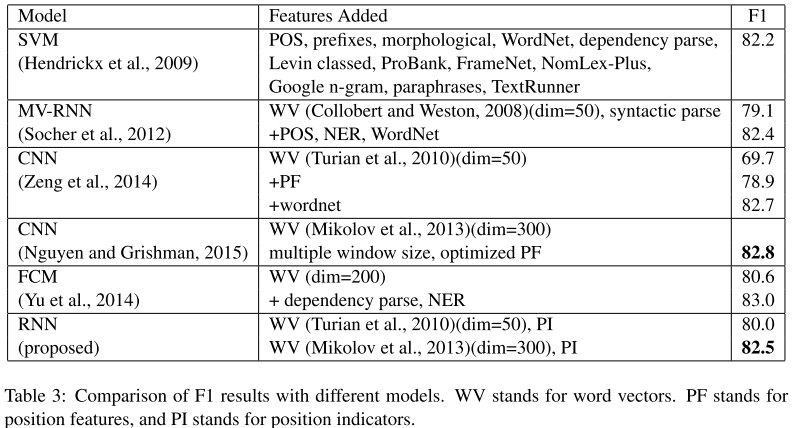
可以看出来,再不使用任何Lexical-Feature的情况下, RNN + PI 与使用多窗口的Zguyen 2015 以及使用 WordNet信息的Zeng 2014达到类似的效果。此外从这几篇文章实验可以看出来,word embedding的size也可以很明显提高F值。
总结
这篇属于使用RNN的尝试,效果与CNN类似。 文中后续还有一些小实验,来说明对长文本建模的时候,RNN的记忆优势就可以体现出来。SemEval 2010 Task 8数据集的句子长度都比较小,因此使用CNN便可以很好的建模。
6. BiLSTM Attention (Zhou 2016)
Zhou. (2016). Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. ACL
这篇文章同样是基于RNN对句子建模,在上一篇RNN的基础上做了一点改进,使用标准的的Attention + BiLSTM,效果与Ranking Loss 类似 84%,基本结构:

主要介绍一下Attention Layer, 其实就是一个对LSTM的每一个step的输出做一个加权的过程,而非仅仅只取最后一个step. 设 \(H=[h_1, h_2, h_3,..h_T]\) 为BiLSTM的所有step的输出矩阵,T为句子长度. 然后经过下面的操作来计算每个step的权重:
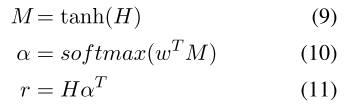
这样\(\alpha\) 就是weight vector, \(r\) 就是最终的Attention-BiLSTM的输出,也即sentence的embedding, 之后使用了softmax来分类,损失函数使用对数似然。
实验
数据集: SemEval 2010 Task 8 dataset 结果:
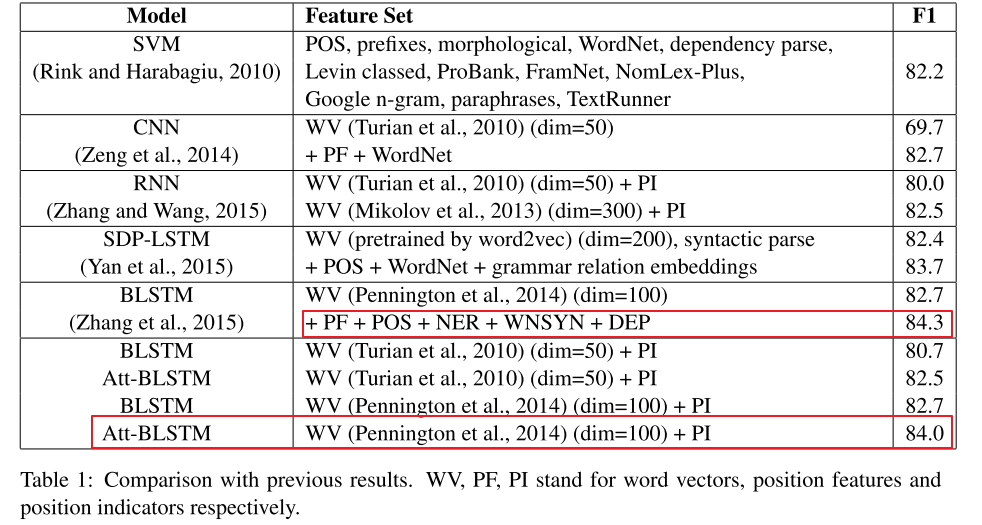
在没有使用词法/语法特征的情况下,达到84%的F1 Score,使用Attention 可以起到作用,能够减弱句子中的噪音词语影响,增强关键词的影响。
总结
Attention + BiLSTM 作为NLP Task的标配,在Relation Classification上也取得了不错的效果。文中不足是仅仅使用标准的Attention+LSTM直接简单用到这个Task, 创新点几乎没有,并没有针对关系分类这个任务的改进。
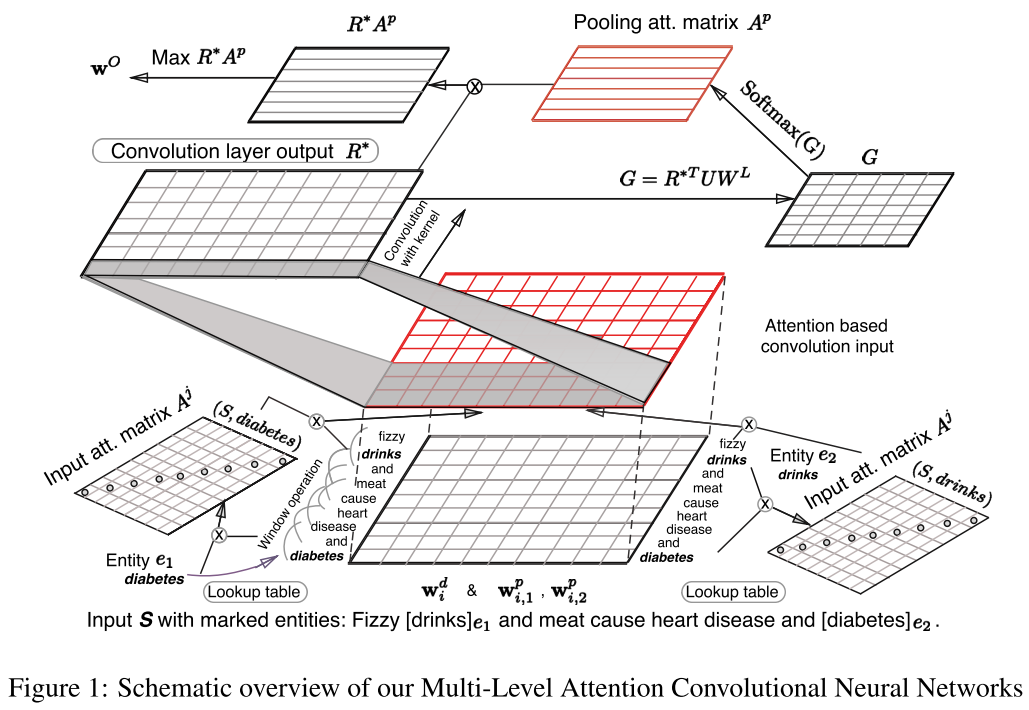
7. Multi-Level Attention CNN (Wang 2016)
Wang. (2016). Relation Classification via Multi-Level Attention CNNs. ACL
这一篇仍然是基于CNN来做的,按照文中实验效果,这一篇目前是最高的F1:88%。设计了相对复杂的两层Attention机制来尽可能突出句子中哪些部分对relation label有更大的贡献。使用了word similarity来定义句子中word与target entity的相似度,从而根据相似度来引入权重,这是第一层的Attention. 第二层Attention则是对卷积之后Pooling阶段,采用Attention Pooling 而不是Max Pooling. 通过这些操作来减弱噪音,加强相关性强的词的权重。此外也改进了前面Santos提出的Ranking Loss. 下面对文中详细介绍.
首先是Input Layer, 同Zeng 2014, 特征仍然是 word embedding + position embedding. 当然word embedding使用的word2vec 进行 pre-train的。因此当前每个词表示为:
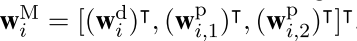
其中\(w_i^d\)为word embedding, 两个\(w_i^{p}\)是Position Embedding。在之后,将trigram信息融合进去,设置一个滑动窗口k,以每个word 为中心,左右k/2个词作为上下文,然后直接串起来,这样每个词的embedding size变为:\((d_w + 2d_p)*k\),如下:
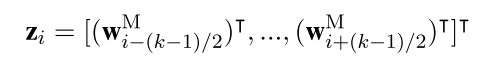
这里需要额外说一句,其实这个n-gram过程现在完成,然后卷积的时候,卷积核的size设置为1就可以了。或者现在不做,卷积核设置为k,可以达到同样的效果。但是后面有Attention,因此在这篇文章中,先做了n-gram。 输入层到这里为止,与其他文章完全一样。 下面就是加入 Input Attention 过程。 首先引入两个对角矩阵\(A_1, A_2\) 对应每个句子的两个entity. 然后使用word embedding的向量内积运算来衡量某个词\(w_i\) 与 entity \(e_j,j =1,2\)的相关性,这样对角矩阵A的元素就是: \(A_{i,i}^{j}= f(e_j, w_i)\),其中f就内积运算。最后使用softamx归一化,来定义Attention的权重:
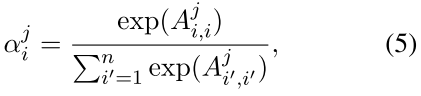
额外补充一句,这里的两个对角矩阵完全可以用两个向量来表示。
每个词都有对两个entity的权重:\(\alpha^{1}, \alpha^{2}\). 这样把权重融合到已经得到的\(z_i\)中。融合的方法文中给了三个:
- average: \(r_i = z_i \frac{\alpha^1_i+\alpha^2_i}{2}\),这种方式直接简单,不过从经验感觉,直接求和比平均要好。
- concat: \(r_i = [(z_i \alpha_i^1)^T, (z_i, \alpha_i^2)T]^T\) 这种方式理论上保留的信息量最大。
- substract: \(r_i = z_i \frac{\alpha^1_i-\alpha^2_i}{2}\) 这种方式其实有点类似于TranE,将relation视为两个权重的差。
这样整个句子表示为: \(R=[r_1, r_2, ..., r_n]\), 至此包含第一层的Attention的Input Layer 完成.
之后是卷积层,这里跟其他文章中卷积相同:
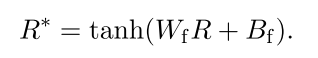
其中 \(W_f\)是卷积核,size为\(d^{c} \times k(d^w+2d^p)\), 前面已经说过了,由于已经在input处做过了tri-gram操作,这里的\(d_c\)一般为1.
后面是第二层Attention Based Pooling; 大部分文章直接使用Max Pooling来处理,这样可能会有一些过于简单,有时候并不能抽出跟后续的relation labels 更相关的部分,这也是这篇文章提出Attention Based Pooling的动机。 定义一个关联矩阵表示卷积之后的结果\(R^{*}\)的每一个元素与relation labels的相关性,如下:

其中U是Attention中的权重矩阵,\(W^L\) 表示relation labels的embedding,跟word/position embedding一样,需要在训练过程更新。这样的G就是一个相关矩阵,每一个元素\(G_{i,j}\)就表示\(R^{*}\)的第i个元素与第j个label的相关性。然后在对G做列归一化:
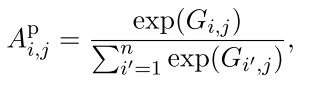
有了Attention Pooling矩阵,在做max pooling:
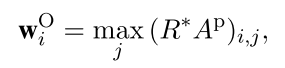
这样得到的输出直接与relation embedding 最相关,\(w_O\)也是模型最后的输出。完整的结构如下, 看起来很复杂,但是每一部分其实都比较简单:
最后介绍模型改进的损失函数,根据Santos 2015提出的Ranking Loss, 这篇文章同样使用margin based ranking loss function. 一般的margin function都需要定义一个distance/score function, 从而来区分正负样例. 在santos文中,直接使用了网络最后的输出score。这篇文章利用relation embedding \(W_{y}^{L}\), 定义了如下的score distance function:
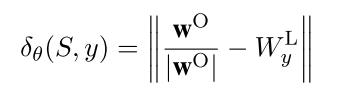
来衡量模型的输出\(w^{O}\)与正确label对应的vector \(W_{y}^{L}\)的相关度,然后就是margin function:
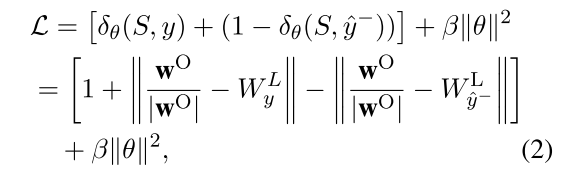
这里直接设置了1为margin,\(y^{-}\)是错误标签,最后用SGD等方法去优化。
实验
数据集同样是: SemEval 2010 Task 8 先看主体实验结果, 最好的达到了88%,比BaseLine 提升非常大:
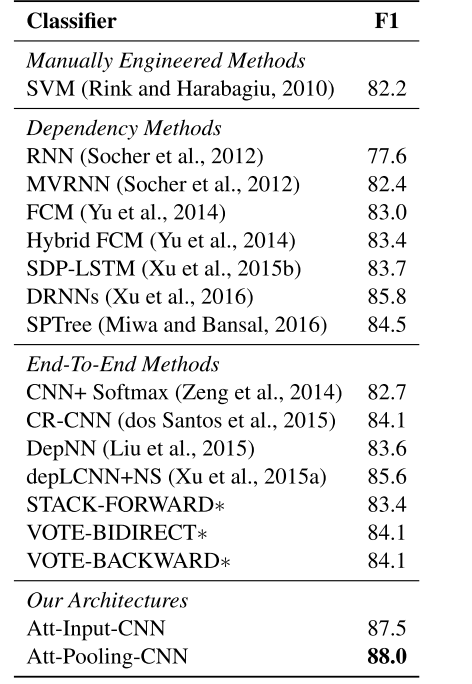
其中仅仅使用Input-Attention可以达到87.5%的效果, 再加上Pooling Attention的效果则达到了88%。从这里可以看出了第一层Attention的作用要更加重要。第二层Pooling复杂度提升很多,performance提升很少。
再看几个对比辅助实验:
Input Attention的三种融合方式, 结果如下:

去掉Pooling Attention, 去掉所有的Attention, 不使用自定义的distance function, 三种结果如下:
 这个结果也可以看出来,第一层的Input Attention 作用很明显。 其中最后一行去掉Attention, 去掉distance function 基本跟Santos 2015那篇文章相同,因此效果也类似。
这个结果也可以看出来,第一层的Input Attention 作用很明显。 其中最后一行去掉Attention, 去掉distance function 基本跟Santos 2015那篇文章相同,因此效果也类似。
总结
优点:
- 两层Attention: 在文章中的两处Attention 均是基于embedding 的内积来运算的。 其中Input Attention 很直观,利用embedding的内积来衡量相关。
- Distance Function:从margin based ranking loss 出发,类似TransE等模型,使用embedding的逼近来作为距离函数。
缺点:
- Input Layer的attention 使用word 与 entity的 embedding similarity 来作为attention的权重,这里有些问题。比如"
caused by " 这里的 caused 很关键,但是与e1, e2的相似度应该比较小。而且不同的词在不同的relation中的重要程度是不一样的。使用统一的embedding 可能会有噪音影响。在一个可能原因是Out Of Vocab 的词语也会降低performance。 - 结构复杂 复杂度高,收敛困难,尤其是第二个Attention
8. Attention CNNs (Zhu 2017)
Zhu, (2017). Relation Classification via Target-Concentrated Attention CNNs. ICONIP
这篇文章基本上是以上一篇为模板,稍微改动了一些, 动机则是每个词在不同的relation有不同的权重Attention 矩阵。 几点不同:
Input Layer 引入一个权重矩阵\(M\),直接计算word 与 relation的相关度, 而不是计算word 与 entity的相关性:
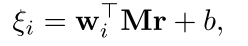
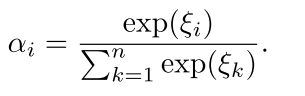
- 去掉了Pool Attention 部分,直接max pooling
目标函数: 没有使用上一篇的自定义的距离函数,而是直接使用类似Santos 2015的那种向量内积计算score的方式. 最终仍然使用ranking loss
实验结果, 并没有对比88%的结果: 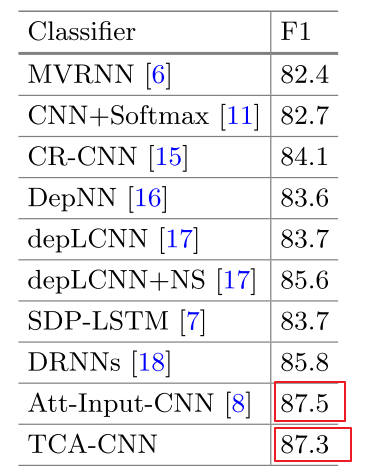
这篇文章在Input Layer的Attention的改进比较符合直观。 在没有使用二级Attention 以及改进的损失函数的情况下, 可以达到87.5%,相对于上一篇的86.1%还是有提升。不过整体来看,文章的创新点比较少。
总结1
目前从论文结果来看,在SemEval 2010 Task 8 数据集上最高的F1-Score为88%,不过貌似还未有人可以复现。 总结一下已有的模型:
- word embedding + position embedding 成为输入层的标配。
- 损失函数Ranking Loss 比 softmax 效果好。
- Attention的作用明显。
- Input Layer加入Attention给每个word赋予weight,可以是word 与 relation的相关性,也可以是word 与 entity的相关性.
- RNN/LSTM的所有step 的输出加一个Attention,本质也属于每个word与relation的相关性。
可能改进的方向: 单纯从神经网络的结构出发,改进的余地很小了,因为这个数据集很封闭, 可以利用的信息仅仅是这些sentence 以及 标注的word entity。 在上述的基础上可能可以考虑的方向,从两个target word与relation的关系上加约束。
Distant Supervised Learning
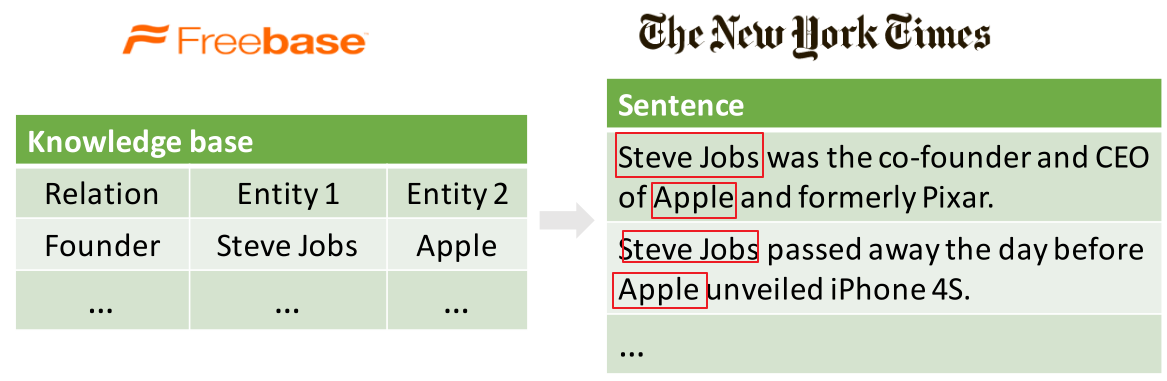
上一章的全监督方法都是在完全正确的标注数据集上来做的,因此数据量很小,SemEval 2010 一共是10000左右条文本。因此开始考虑研究如何在大数据集上做关系抽取。2010年提出Distant Supervision可以自动标注训练样本,原理很简单。利用知识图谱中的两个entity以及对应的某个relation,在corpus中进行回标,如果某个句子中同时包含了两个entity,那么就假定这个句子包含了上述的relation. 这样就可以获得大量的标注数据。当然缺陷就是假设太强,会引入了很多噪音数据, 因为包含两个entity的句子不一定可以刻画对应的relation,如下, 对于NYT 语料中的第一个句子的确描述了 Founder的关系,但是第二句就不是这个关系,因此属于噪音:
在2011年提出了Multi Instance Learning的方法来改进原始的Distance supervision的方法,有一个At-Least-One 的前提: 包含两个entity的所有句子中,至少有一个句子可以体现relation,即至少有一个标注正确的句子。通过结合FreeBase 对NYT语料做Entity Linking,Relation Aligning等操作进行标注, 最终得到一个被广泛使用的关系抽取数据集, 在开始已经描述过详情。正如前面声明,这里面会有噪音数据。 因此在这一系列的文章中,都会针对该噪音问题做一些工作,其中大部分基于Multi Instance来做。简单引用介绍Multi Instance Learning:
多示例学习可以被描述为:假设训练数据集中的每个数据是一个包(Bag),每个包都是一个示例(instance)的集合,每个包都有一个训练标记,而包中的示例是没有标记的;如果包中至少存在一个正标记的示例,则包被赋予正标记;而对于一个有负标记的包,其中所有的示例均为负标记。(这里说包中的示例没有标记,而后面又说包中至少存在一个正标记的示例时包为正标记包,是相对训练而言的,也就是说训练的时候是没有给示例标记的,只是给了包的标记,但是示例的标记是确实存在的,存在正负示例来判断正负类别)。通过定义可以看出,与监督学习相比,多示例学习数据集中的样本示例的标记是未知的,而监督学习的训练样本集中,每个示例都有一个一已知的标记;与非监督学习相比,多示例学习仅仅只有包的标记是已知的,而非监督学习样本所有示例均没有标记。但是多示例学习有个特点就是它广泛存在真实的世界中,潜在的应用前景非常大。 from http://blog.csdn.net/tkingreturn/article/details/39959931
从这个介绍中可以看出来在Multi Instance Learning很适合用在NYT+FreeBase数据集上。
相关文献
1.Piecewise Convolutional Neural Networks
Zeng (2015). Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. EMNLP
这一篇工作是在Zeng 2014基础上的扩展,从Fully Supervised 到Distant Supervised. 动机
- Distant supervised 会产生有大量噪音或者被错误标注的数据,直接使用supervised的方法进行关系分类,效果很差。
- 原始方法大都是基于词法、句法特征来处理, 无法自动提取特征。而且句法树等特征在句子长度边长的话,正确率很显著下降。
因此文中使用Multi Instance Learning的at least one假设来解决第一个问题; 在Zeng 2014 的CNN基础上修改了Pooling的方式,解决第二个问题。 先介绍改进的CNN: Piece Wise CNN(PCNN). 总体结构如下, 与Zeng 2014 很类似:
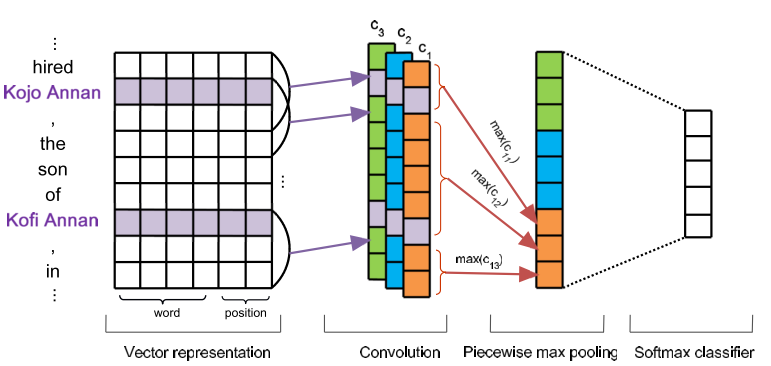
输入仍然是一个sentence,Input Layer依然是word embedding + position embedding, 后面接卷积操作。 之后的Pooling层并没有直接使用全局的Max Pooling, 而是局部的max pooling. 文中把一个句子分为三部分,以两个entity为边界把句子分为三段,然后卷积之后对每一段取max pooling, 这样可以得到三个值,相比传统的max-pooling 每个卷积核只能得到一个值,这样可以更加充分有效的得到句子特征信息。 假设一共有个N个卷积核,最终pooling之后得到的sentence embedding的size为: \(3N\), 后面再加softmax进行分类,最终得到输出向量\(o\), 上面的示意图很清晰了,其中的c1,c2,c3是不同卷积核的结果,然后都分为3段进行Pooling。 下面可以减弱错误label问题的Multi-Instance Learning。这里面有一个概念, 数据中包含两个entity的所有句子称为一个Bag。先做几个定义:
- \(M={M_1, M_2, ..., M_T}\) 表示训练数据中的T个bags,每个bags都有一个relation标签.
- \(M_i = {m_i^{1}, m_i^{2},...,m_i^{q_i}}\) 表示第i个bag内有\(q_i\)个instance,也就是句子。
- $o $ 表示给定\(m_i\)的网络模型的输出(未经过softmax),其中\(o_r\) 表示第\(r\)个relation的score
这样经过softmax 就可以计算每一个类别的概率了
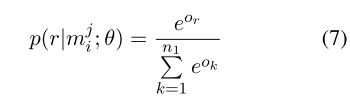
这里需要说明的是,我们的目的得到每个bag的标签,并不关注bag里面instances的。因为每个bag上的label就是两个entity的relation。 而上面的概率是计算的bag里面某一个instance的,所以需要定义基于Bag的损失函数,文中采取的措施是根据At-Least-One的假设,每个Bag都有至少有一个标注正确的句子,这样就可以从每个bag中找一个得分最高的句子来表示整个bag,于是定义如下的目标函数: 假设训练数据为T个bags: \(<M_i, y_i>\):
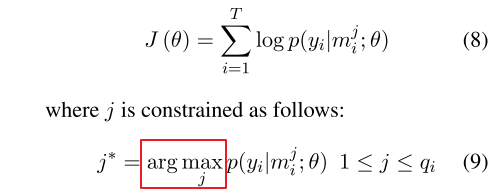
这样到此为止,模型部分完毕,完整的算法如下:

实验
数据集: NYT+FreeBase,过滤掉了样本少的关系,最后使用了26类关系,数据描述如下:

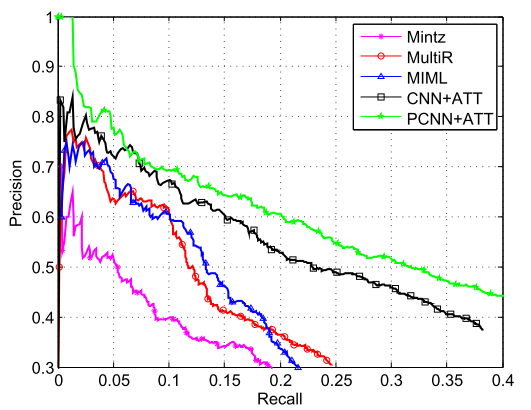
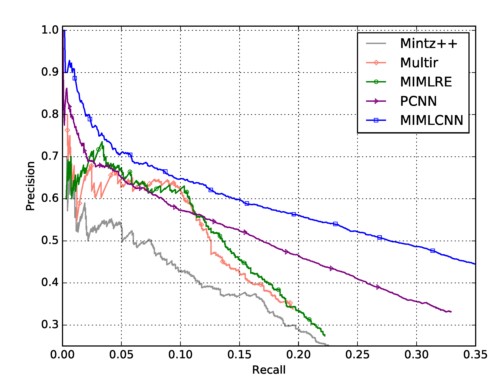
评测: - Held-Out Evaluation: 直接在Test Dataset上进行评估,使用多分类的Precision-Recall Curve(基于不同的分类阈值)来衡量, PR曲线越靠近右上,证明分类效果越好: 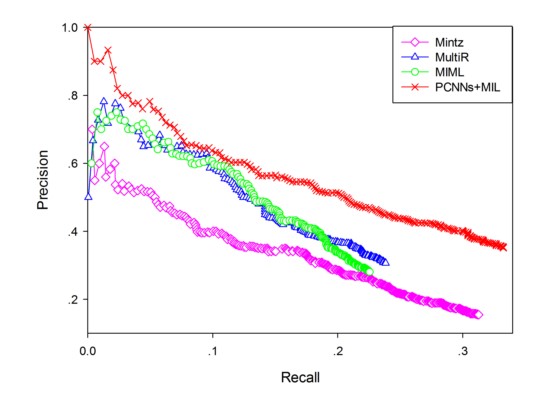 可以看出来,PCNN + MIL 表现最好,Precision和recall都要优于baseline。 - Manual Evaluation: 考虑到FreeBase 还不够完备,对于分类为False Negatives的数据,有可能是两个entity有关系,但是在FreeBase中并没有收录。 从上图的PR-Curve中也可以看出来,recall相对很小,一部分原因是FN过大,尤其是将NA分为其他的relation。 因此文中对那些将NA分为其他类别,按照概率高低,排序,手工检查Top-K 里面的entity pair是否的确有关系,结果如下:
可以看出来,PCNN + MIL 表现最好,Precision和recall都要优于baseline。 - Manual Evaluation: 考虑到FreeBase 还不够完备,对于分类为False Negatives的数据,有可能是两个entity有关系,但是在FreeBase中并没有收录。 从上图的PR-Curve中也可以看出来,recall相对很小,一部分原因是FN过大,尤其是将NA分为其他的relation。 因此文中对那些将NA分为其他类别,按照概率高低,排序,手工检查Top-K 里面的entity pair是否的确有关系,结果如下:  结果显示PCNN取得了最好的效果。 - 辅助对比实验:原始的CNNs, CNNs + Multi Instance, PCNNs, 以及 PCNNs+Multi Instance的结果:
结果显示PCNN取得了最好的效果。 - 辅助对比实验:原始的CNNs, CNNs + Multi Instance, PCNNs, 以及 PCNNs+Multi Instance的结果: 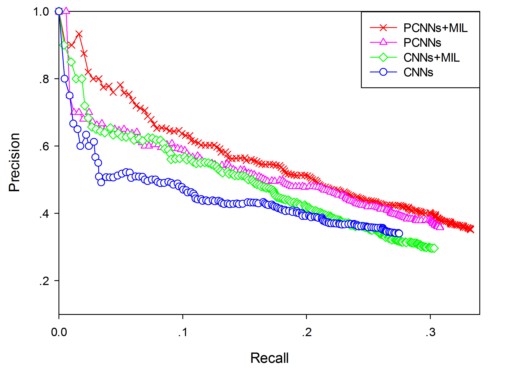 可以看出来, 文中提出的两种改进的确都有效果。
可以看出来, 文中提出的两种改进的确都有效果。
总结
这篇文章在NYT + FreeBase 数据集上比较好的效果, 也是第一篇使用CNN+Multi Instance来处理Distant Supervision 的关系抽取。相比与Zeng 2014,将Piecewise Pooling 加入到CNN中,以及将Multi Instance来处理Distance Supervised,从而减弱噪音的影响。当然在MIL中直接取了置信度最高的instance作为bag的,肯定会损失一部分信息,因此后续一些文章在上面做了工作。
2.Selective Attention over Instances (Lin 2016)
Lin (2016). Neural Relation Extraction with Selective Attention over Instances.ACL
这一篇文章在上一篇Zeng 2015的基础上引入了Attention机制。
动机
在Zeng 2015中的MIL部分,每一个bag仅仅取了置信度最高的instance,这样会丢失很多的信息,因此一个bag内可能有很多个positive instance。应用Attention机制可以减弱噪音,加强正样本,因此可以更充分的利用信息。
模型 总体结构:
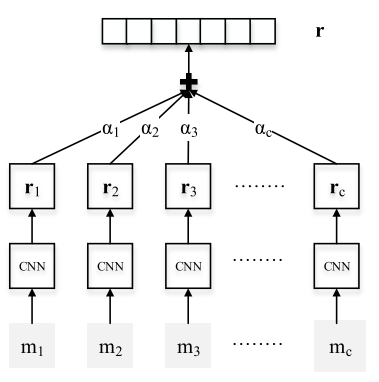
其中\(m_i\)是某一个bag的instance,图中的CNN模块与Zeng 2015 (PCNNs)的结果相同(Embedding Layer->Convolution Layer -> Piecewise Max Pooling Layer) 最终得到每个句子的表示\(r_i\)。为了能够充分的利用bag内的信息,我们可以对所有instance取加权: \(s= \sum_{i} \alpha_i x_i\) 其中\(\alpha\)是权重比例,文中给出了两种定义权重的方法:
- Average: 直接取平均: \(s=\sum\frac{1}{n}x_i\) ,这种将所有instance同等对待的方式还是有缺陷,放大了噪音影响。
- Attention: 目标是增加positive instance的权重,减小noise instance的权重。但是并不知道每个instance的groud truth,但是知道每个bag的label,因此就可以用instance 与 该relation label的相关度大小引入Attention: 如下:
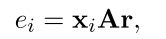
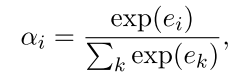 其中A为Attention对角矩阵,\(r\)可以认为是该数据的relation标签的embedding向量。 这样\(e_i\)就可以一定程度表示句子与标签的相关性。
其中A为Attention对角矩阵,\(r\)可以认为是该数据的relation标签的embedding向量。 这样\(e_i\)就可以一定程度表示句子与标签的相关性。
之后得到了加权的\(s\)就是bag-level的embedding。最后的输出需要注意,并不是直接用一个全连接层+softmax.而是根据向量的相似度计算bag的emebdding 与 每个relation的相似度作为relation的score,比如relation r的score计算方式:\(o_r = v_r s + b\) 这里的b是一个bias,每个relation的score计算完之后,利用softmax来归一化成概率: 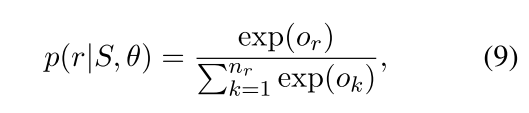
在Test阶段不太一样, 前面说了在计算Attention的时候,使用的是训练数据对应的label 的embedding,但是在test的时候,并没有标签。文中的处理方式是: 对每一个relation r 执行下面的操作:
- 计算一个bag里面所有的句子x与r的Attention权重,这一步与训练相同,然后加权求得这个bag的表示\(s\)
- 计算式子10: \(o = Ms +d\), 这里的M就是所有relation的embedding 矩阵。 这样得到了 o 是一个\(N_r\) 维度的向量,\(N_r\)是relation的number。
- 取出o里面的relation \(r\) 对应的值, 作为这个r的预测概率
源码注释如下: 
遍历完所有的relation之后, 得到每个relation的概率,取max即可。 这个过程其实相当于一个遍历的过程,复杂度有点高,而且解释性比较差,是一个可以改进的一个地方。
实验
文中首先做了在CNN/PCNN的基础上,如何使用bag内的信息的对比试验,结果如下,其中CNN/PCNN表示没有引入MIL,+ONE表示ZENG2015的取置信度最高的一个,+AVE与+ATT则是文中提出的两个:
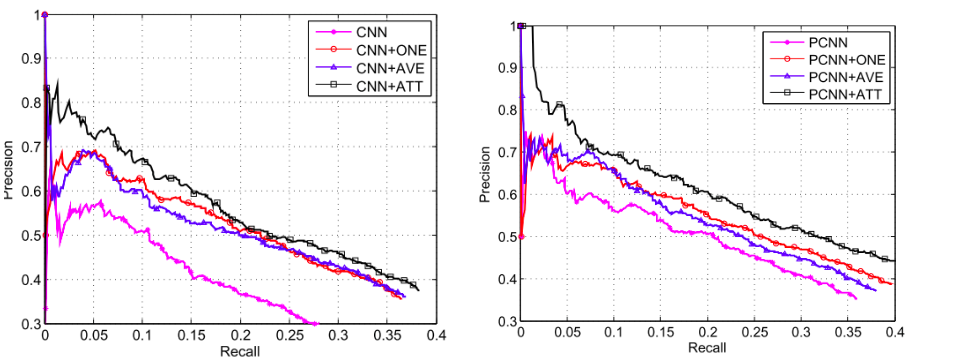
可以看出来,Attention的效果最好, 而且+ONE比+AVE要稍微好一些,也很容易理解,+AVE对噪音数据放大了影响。 第二个对比实验则是与传统方法的对比:
最后一组实验则是更进一步验证Attention的作用。 因为在测试数据中,有超过3/4的bags 只有一个句子。 因此文中把拥有多个句子的entity pair 提取出来验证效果,在该子集上使用一下三种设置:
- One: 表示在每个bag里面随机选择一个句子来进行预测
- Two: 表示在每个bag里面随机选择两个句子来进行预测
- All: 使用bag里面所有的句子来进行测试
评价指标使用P@N,结果如下:
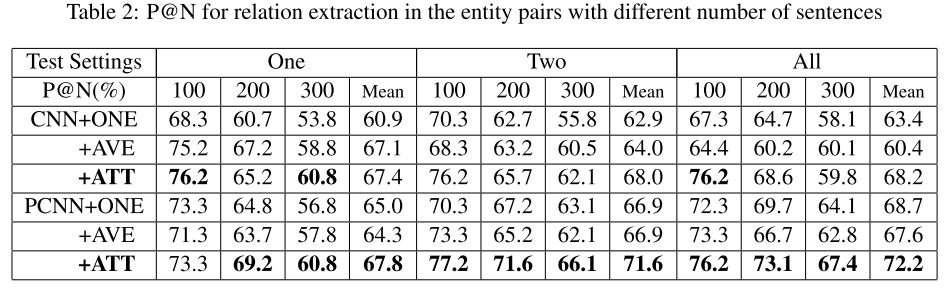
从结果可以看出来,ATT的确表现最好。
总结
与上一章全监督一样,Attention的作用很明显,而且用在这里很直观, 对bag内的句子赋予不同的权重,一方面可以过滤噪音,又可以充分利用信息。
不足的地方:
- 正如在future work上所述,还是基于Zeng2014/5的基本框架上做改进,这个数据集句子长度要比SemEval 2010要长很多, 可以考虑用RNNs来测试结果如何。一般情况CNN在短文本效果比较好,RNN在长文本略有优势。
- 上面说的,train过程和test过程不一样,test要更加复杂,复杂度要高很多。
3.Multi-instance Multi-label CNNs (Jiang et al., 2016)
Jiang (2016). Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks. Coling
这篇文章从另一个角度来解决Zeng 2015的问题,并且考虑了实体对的多关系的问题。
动机
- Zeng 2015里面仅仅取置信度最高的instance,丢失信息。
- 在数据集中,有约18.3%的entity pair有多种relation, 其他方法均未考虑。
模型
针对以上的两个问题提出了两个解决方法:
- 对bag内部的所有sentence embeding做instance-max-pooling的操作,具体细节后面介绍
- 对于多标签,使用多个二分类函数来做多标签分类,即: 使用sigmod计算每一个类别的概率, 然后判断该bag是否可能有这种关系。
模型的结构如图:
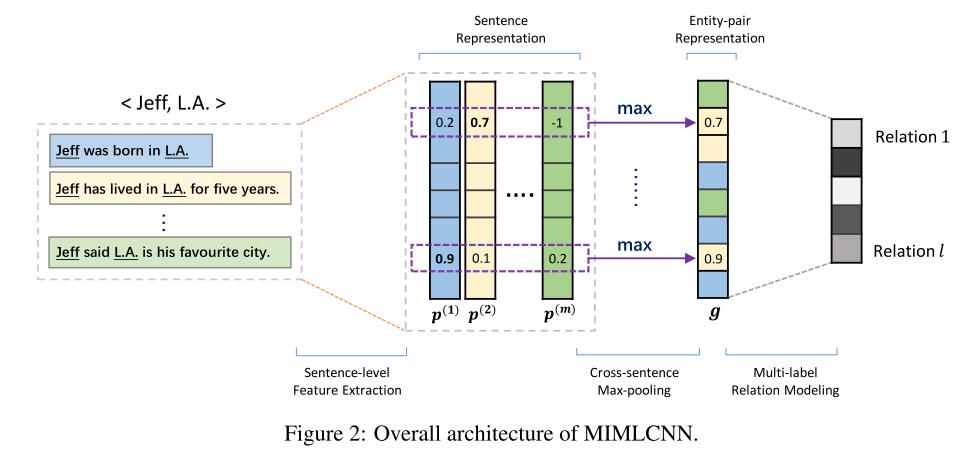
输入也是一个bag,然后利用CNN/PCNN来计算每个sentence的embedding,之后的融合方式很直接,直接对embedding的每一维度取所有sentence的对应维度的最大值。
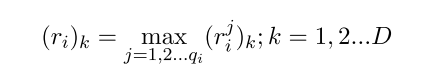
其中k表示embedding的某一维度,\(j\)表示bag中的第j个句子。 这样就可以融合所有sentence的信息了。后面加一个全连接层计算每一个类别的score:
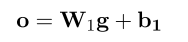
之后不再是加softmax多分类了,而是使用sigmod函数计算每个relation的概率,然后超过某个阈值,就认为该relation是准确的:
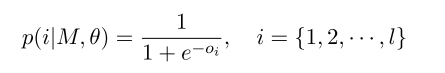
其中\(l\)就是类别的总数。 文中设计了两种损失函数来做对比, Sigmod Loss Vs Squared Loss:
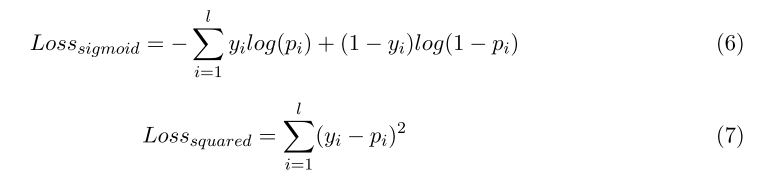
实验 直接看P-R Curve结果,相比PCNN提升比较明显:
再看取max的设计的作用,与直接取平均对比, 这里有点需要说明,在这个实验中,取平均要比PCNN效果好,而在上一篇平均效果差, 这说明的是multi label有提升的作用:
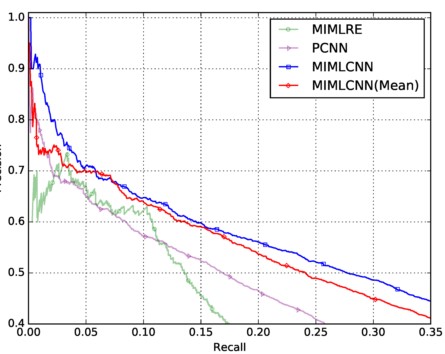
最后一个是两种损失函数的对比:
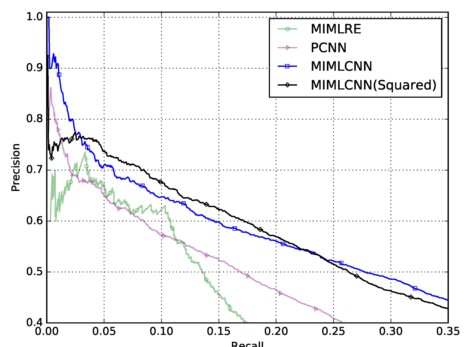
可以看出,二者在不同的区域各自有优势。
总结
仅仅对bags内的sentence的每一维度取了最大值,就可以得到一个很不错的效果, 可以考虑其他稍微复杂一些的融合方式,从而得到更多的信息,Attention仅仅取权重,其实还是属于线性融合。此外这篇文章仍然也是在该CNN/PCNN基础上进行扩展,从这一点来说创新性有些少。 不过文中提出的Multi Label 则是一个新的方向.
4.Memory Network based (Feng 2017)
Feng,(2017). Effective deep memory networks for distant supervised relation extraction. IJCAI
这篇文章使用2014年提出的Memory Network的思想来做关系抽取。
动机
- 不同的word在不同relation下以及对不同的entity pair 重要程度不同,这一点类似于Fully Supervised 中的Multi-Level Attention
- relation之间并不是独立的,会有overlap, 也就是上一篇提出的多标签。本质上是因为标签之间有相互依赖关系,如(A, capital, B) 成立的话, (A, contains, B)也会成立。
对于第一个问题,借鉴了Multi-Level Attention的input layer attention的思路,即根据word 与 entity pair的相似度,来分配权重,但是这里不使用传统的Attention, 而是基于Memory Network的思想,关于Memory Network的细节,这里不介绍,不了解也不影响对文章的理解。 对于第二个问题,文中使用relation-level的attention 来引入relation之间相关度,下面详细介绍
模型
跟前面的文章类似, 本文也是分为两个大模块,sentence representation 以及 relation classification。 首先从input layer 开始,每个word仍然由word embedding + position embedding两部分组成。 在本文中sentence embedding由两部分组成,其中一部分是传统的CNN/PCNN(Zeng 2015) 中得到的输出,这一块不再赘述,与上面文章相同。 另一部分则是考虑了句子中entity的上下文与entity的相关性得到的一个表示,细节如下:
设每个句子表示为\(S=\{e_1,e_2,..,e_l\}\),其中\(e_i \in R^{d \times1}, d=d_w + 2d_p\), \(l\)表示句子长度。 两个entity为\(e_h, e_t\),这样剩下的部分,也就是上下文,表示成一个矩阵:\(m=\{e_1,..,e_{h-1}, e_{h+1},...,e_{t-1},e_{t+1}..\} \in R^{d \times (l-2)}\),文中成为 external memory 矩阵 然后计算\(m\) 的每一行也就是每一个上下文与entity pair的相关度,这里并没有使用向量内积来运算,而是一层神经网络来计算score: \[g_i = tanh(W_{word-ep}[m_i, e_h, e_t] + b_{word-ep})\] 其中\([x1,x2]\)表示向量串联,\(W_{word-ep} \in R^{1 \times 3d}, b_{word-ep} \in R^{1\times 1}\), 再使用softmax来得到权重: \[\alpha_i = \frac{\exp(g_i)}{\sum \exp(g_j)}\]
最后可以得到一个加权之后的输出向量:\(x=\sum_{i=1}^{l-2} \alpha_i m_i\). 在x的基础上,还可以继续上述的过程,只是把entity pair的两个向量,换成\(x\). 可以重复多次,最终得到一个输出作为sentence的另一部分表示。 将该部分与CNN的输出直接串联作为最终句子的表示。
对于一个bag来说,使用上面的模型可以得到每个句子的表示,之后文中使用两阶段的Attention: - Selective Attention over Instances 与Lin 2016 相同, 对每个bag内的instances取加权平均,计算方法也一样,首先利用Attention矩阵计算instance与每个relation的相关性: \(z_i = x_i A v_{r_j}\), 之后进行softmax计算权重: \(\beta_i = \frac{\exp(z_i)}{\sum \exp (z_p)}\) , 最终得到加权的bag表示: \(R_{j}=\sum \beta_i x_i\),其中\(R_j\)是relation-specific的 - Selective Attention over Relations 这一层的Attention是用在relations之间的,用来挖掘relation之间的依赖关系,前一层的Attention得到了k个向量:\(R=\{R_1,...,R_k\}\),其中k为relation 数量。 计算关系 i 与 j 的相关性如下: \(h_i = R_i B R_j\), 之后softmax 计算权重: \(\gamma_i = \frac{\exp(h_i)}{\sum \exp (h_q)}\), 然后就可以得到融合多relation依赖关系的输出: \(R^{*}_{j} = \sum_{i=1}^{k} = \gamma_i R^i\)
之后得到\(R={R_{1}^{*}, ..., R_{k}^{*}}\),对每一个relation 做一个binary classifier, 逻辑回归的sigmod即可 \[p(i|M,\theta)=\frac{1}{1+\exp(-o_i)}\] 其中\(o_i = W_i R^{*}_{i} + b_i\) , 最后使用多标签的损失函数,与上一篇相同:

到此模型介绍完毕。
实验
同样用held-out以及P@N 结果如下:

从结果看, 本文的方法比Lin 2016 要好, 毕竟考虑了关系的依赖性,不过提升不是很明显,可能原因是数据问题,relation的overlapping比较少。 再看一组对比实验: 分别是去掉word-attention 以及去掉 relation-attention:
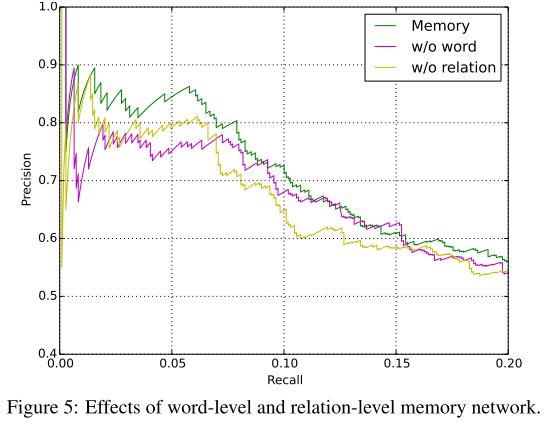
可以看出来,去掉relation之后,下降相对来说比去掉word-level更加明显。
总结 这篇文章虽然以Memory Network 为题,不过可以本质还是用Attention引入相关性。 word-level的动机来自Multi-Level 的那篇文章,计算word与target entity的相关性,并且可以多层,从而挖掘更深层次的关系。relation-level的动机则是考虑到数据中的关系依赖性,使用attention来考虑关系之间的相关性。
这篇文章创新的地方在于引入relation之间的依赖关系。 可能改进的地方有,完全从embedding的角度考虑相关性,抛弃Attention,计算量会少一些。包括word-entity embedding; relation-relation embedding;
5.Multi-Instance With extra Entity Descriptin (Ji 2017)
Ji (2017). Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. AAAI
这篇文章引入了额外的Knowledge Graph 信息: 实体描述(entity Description). 比如NYT 数据集是通过Freebase做entity linking等工具来进行连接出句子中的实体,而其实每个实体在FB都有一段文字描述, 文中认为现在的工作都集中在NYT + Freebase数据本身上,却忽略了该数据集中背后的KG信息,其中就有实体的描述信息。因此本文在之前的工作基础上引入了实体描述信息,加强对实体embedding的学习。此外,在处理Multi Instance Learning方面, 本文同样使用了Sentence-Level Attention的机制,类似Lin 2016.
模型
模型分为三部分: 输入模块,Attention 模块, Entity 描述模块。 输入层,每个句子的每个词由word embedding + position embedding 连接表示,这里与其他模型完全一样,不再赘述。 接着是卷积层与Piecewise Max-Pooling层,到这里与PCNN(Zeng 2014)完全一致,最终得到每个句子的embedding。 下面则是用来解决Multi instance Learning的Attention 模块。 计算bag内的每个Instance 与 relation的相关性,确定权重。具体步骤如下:
- 计算相关性: \(\omega_i = W^T_{a}(tanh([b_i; v_{relation}])) + b_a\) 其中\([x1, x_2]\)表示concat操作, \(b_i\)表示上一个步骤得到每个句子的表示,与Lin 2016 使用随机初始化作为\(v_{relation}\)的参数不同的是,这里的\(v_{relation}\)借鉴KG Embedding的Trans模型,即: \(v_{relation}=e_1 - e_2\)。此外这里使用神经网络计算Attention。
- 归一化: \(\alpha_i = \frac{\exp(\omega_i)}{\sum \exp(\omega_j)}\)
- 加权句子表示,得到bag的表示: \(b = \sum \alpha_i b_i\)
后面同样加一个softmax层用来做多分类: \(o = W_s b + b_s\), 归一化: \(p(r_i) = \frac{\exp(o_i)}{\sum \exp(o_j)}\) 到这里为止其实与前面的工作相似度非常高, 仅仅是Attention的一点差异。下面介绍文中引入的Entity Description部分。 其实很简单,步骤如下:
- 使用普通的一层CNN+MaxPooling 对 description 建模得到 描述的 embedding向量,假设\(d_i\)为第i个实体的description embedding
- 文中提出的一个约束是:尽可能使得前面得到的entity的word embedding 与 这里得到的 entity 的 description embedding 接近,这样的动机很简单,就是将entity的描述信息融入到模型中,这部分的LOSS直接使用二范距离: \(L_e = \sum ||e_i - d_i||_2^2\)
最终的目标函数,就是将两个损失函数联合训练: \[\min L = L_A + \lambda L_e\] 其中\(L_A = \sum log P(r_i), \lambda\)为调节系数。
实验
数据集说明:
- NYT + FreeBase
- 从Freebase 以及 Wikidata中提取出的实体描述
首先看Held-Out 实验结果:
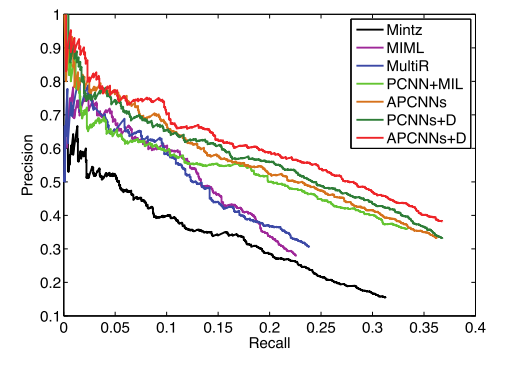
其中实验有: PCNN+MIL 为Zeng 2015的模型, APCNNs为本文提出的不包含实体描述的模型, PCNNs+MIL+D为在zeng 2015的基础上加上实体描述的Loss,APCNNs+D为本文包含描述的模型。 可以看出来加上实体描述的确对效果有提升。此外APCNNs 比 PCNN+MIL要好一些,说明Attention要比取置信度最高的instance要好。
再看manual实验,就是找出那些标签为NA但是预测非NA的数据, 人工检查,检查是否两个entity的确有预测的relation,使用准确率Accuracy来衡量,结果如下,这里的top是指按照预测为某relation的概率大小排序:

总结
这篇文章的贡献主要在从KG中引入额外的实体描述信息,加强embedding的学习。 不过两部分的融合有点简单暴力,本质上相当于在原来的基础上加了一个范式约束而已,或者说一个先验的惩罚项, 这种方式提供了一个比较好的思路, 扩展性很强.
总结2
general的总结:
- 输入层: 基本word embedding + position emebdding
- Sentence Embedding: 基本使用CNN/PCNN
- Multi Instance Learning: 基本使用Attention 来处理(Attention的选择有待改进)
- Evaluate:
- Held-out: P-R 曲线
- Manual: 选择Negative False的标签为NA的数据, 手工检测是否的确为NA
其他Tips:
- Word-Entity的相关度,同一个word在不同的entity pair内有不同的重要性。(Deep Memory Network, Multi-Level Att )
- Word-Relation的相关度,同一个word在不同的relation下有不同的重要性。()
- 多标签分类(MIMLCNN, Memory Network)
- relation之间的依赖性(Memory Network)
附
关系抽取这个方向相对来说比较成熟了, 包括数据集,评测等. 改进的出发点很多; 相对比较容易做的就是从distant supervision下手, 如何减轻噪音数据带来的影响. 此外用一些时髦的东西套过来也可以,比如强化学习(AAAI2018有2篇)
此外正在用Pytorch来复现相关模型, 然而一些经典模型仍然无法复现出结果, 还在调试.
大概原因找到了, 数据集的问题。 在NYT数据集上,常用的有两个版本的数据集(刘康老师组他们在AAAI2018的文章 Large Scaled Relation Extraction with Reinforcement Learning Task 也提到了):
- 27类关系,Zeng2015,Ji2017等用到的经过过滤之后的数据集,相对较小,以SMALL表示。
- 53类关系,Lin2016 发布的数据集,相对较大,训练数据大概是小数据的4倍,以LARGE表示。
根据个人及同学的使用Pytorch复现的实验结果,代码:pytorch-relation-extraction, 有下面经验结论(可能有误差):
- PCNN+ATT(Lin 2016) 在SMALL数据集上很难达到在LARGE数据集上的效果,甚至达不到PCNN+ONE(Zeng 2015)的效果, 原因正在探索
- 在LARGE数据集上,复现的模型中, PCNN+ATT可以达到Lin 2016文中的效果,PCNN+ONE在该版本数据集上的表现也比SMALL数据集要好, 而且基本与PCNN+ATT持平。
完整实验情况见: 关系抽取实验
鉴于上述的发现,正好也有个很有趣的现象与之对应,使用SMALL数据集的文章貌似没有与PCNN+ATT这一经典模型做对比实验的。另外在刘康老师组的AAAI2018的文中,也是在两个数据集上分开比较的,仅仅在LARGE数据集上与PCNN+ATT模型做了对比。
...待续