对近几年推荐系统(Recommendation System)领域结合Knowledge Graph Embedding (知识图谱表示学习) 或者 Network Embedding(网络表示)的几篇论文做了极简介绍。 首先对简单介绍推荐系统,之后整理了几篇结合知识表示的论文。
推荐系统简介
一句话来介绍的话,就是通过分析历史数据,来给用户 推荐 可能会喜欢/购买的商品, 这里面的核心就是用户 (User) 和 商品 (Item)。 更进一步,推荐系统的关键有下面三部分:
- 用户偏好建模:User Preference
- 商品特征建模: Item Feature
- 交互: Interaction
在RS中,具体的问题有多种,这篇笔记暂时侧重于Click-Through-Rate(点击预测) 问题,即根据用户历史点击/购买的Item列表,来预测 是否会点击/购买当前item,因此不考虑user的一些属性因素的话,本质就是判断历史item集合与当前新的item的相似度。
因此item的建模比较关键,在推荐系统中,目前不少工作开始融合一些结构信息来提高性能与解释性,至于如何建模结构,个人理解已有工作大概可以分为两种类型:
- 结合知识图谱(Knowledge Graph)
- 结合异质信息网络 (Heterogenerous Network)
本篇笔记主要集中在推荐系统结合知识图谱的几篇工作做个非常简单的总结,后续如时间允许,会将这一系列补全。
论文
CKE
Zhang F, Yuan N J, Lian D, et al. Collaborative knowledge base embedding for recommender systems[C]// KDD, 2016: 353-362.
问题:给用户推荐 一个商品列表, 评价指标是使用Map@K: Recall@K 。
总览
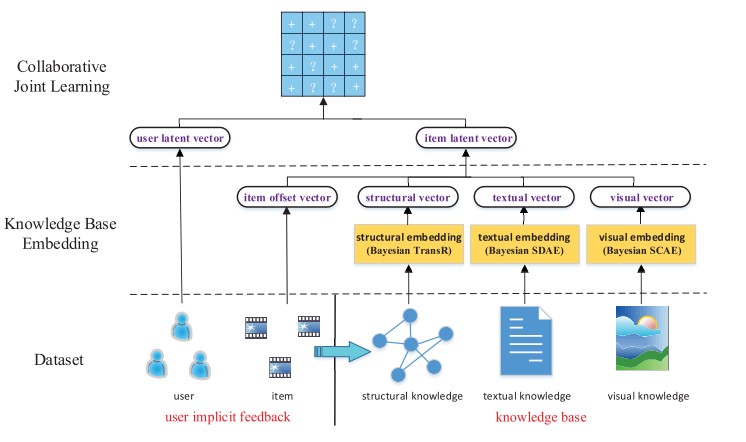
使用item各种外部辅助信息来融合到CF中, 包含:
- 结构信息: 异质结构信息(知识图谱),如 (演员-》出演-电影)
- 文本信息: item的文本描述,如电影的文字简介。
- 图片信息: item的图片,如电影海报
其中编码方式:
- 结构信息: TransE/R
- 文本信息/图片信息: SDAE(堆叠自动编码)
得到关于item的三种Embedding,与CF的latent factor 加起来,得到item最终的embedding 用户:仅仅有CF的latent factor.
得到item和user的Embedding之后, loss则使用pair-wise 的rankinig loss. 此外需要注意的是,CF过程中 user/item的交互是通过评分矩阵来的, 这里仅仅使用了Postive的评分信息(不小于3)。
评价
- 局限性稍微大,需要大量的知识图谱中的额外信息,在实际的推荐中不易获得。
- 融合方法略微简略粗暴,直接使用向量相加
DKN
Wang H, Zhang F, Xie X, et al. Dkn: Deep knowledge-aware network for news recommendation[C]//WWW, 2018: 1835-1844.
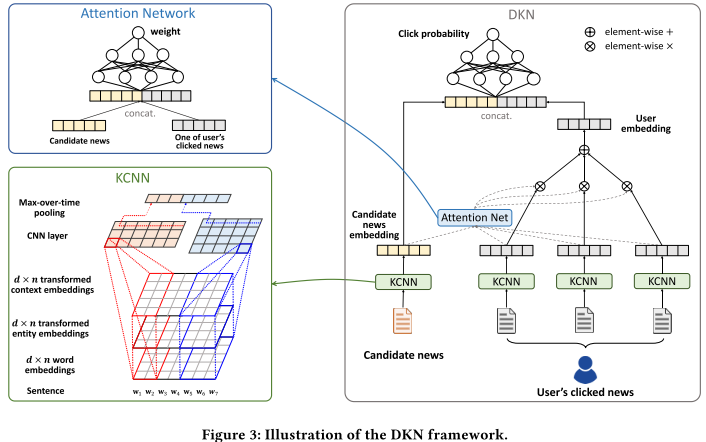
本篇文章侧重于新闻推荐场景,将KG Embedding结合到CTR中(预训练的方式), 基本结合用户点击的历史新闻纪录,来判断是否会点击新的新闻。 本质上相当与 判断 历史新闻集合与新的新闻的相似度。 动机如下图,通过提取新闻标题中的实体,接着通过知识图谱来传递相关其他新闻,如下图: 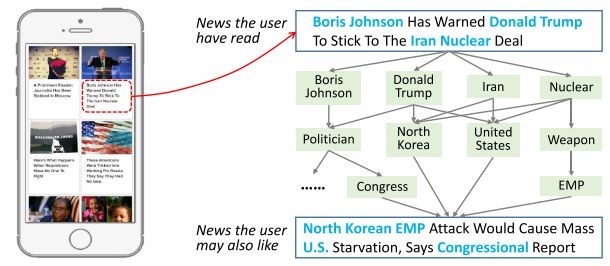
下面介绍模型的主要部分。
Multi Channel CNN
类似RGB的3通道: 作为CNN的输入(文本为新闻title)
- word embedding: 词的word embedding
- entity emebdding: KG Embedding得到的 entity embedding. 对于非实体的词,直接补全为0即可.
- entity context embedding: 对于实体词,其在知识图谱中的一阶邻居实体平均embedding作为补充信息
组成三通道作为cnn的输入
User-Candidate News Attention
- Attention计算:将u点击的新闻与候选新闻embedding进行连接,输入到DNN
- Query Vector: 候选新闻的标题特征
- Key/Value:用户点击的所有历史新闻的标题特征
- 加权求得用户的点击偏好
- 是否点击二分类:aggreate得到user embedding 与 候选新闻进行 相似度计算,这里还是使用dnn
总结
本篇文章更加侧重于对短文本的建模,三通道CNN那里很有技巧性,可以借鉴到其他领域。此外attention的计算方法(target item 为query,history items 为 key) 应用也比较广泛。
RippleNet
Wang H, Zhang F, Wang J, et al. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems[C]//CIKM, 2018: 417-426.
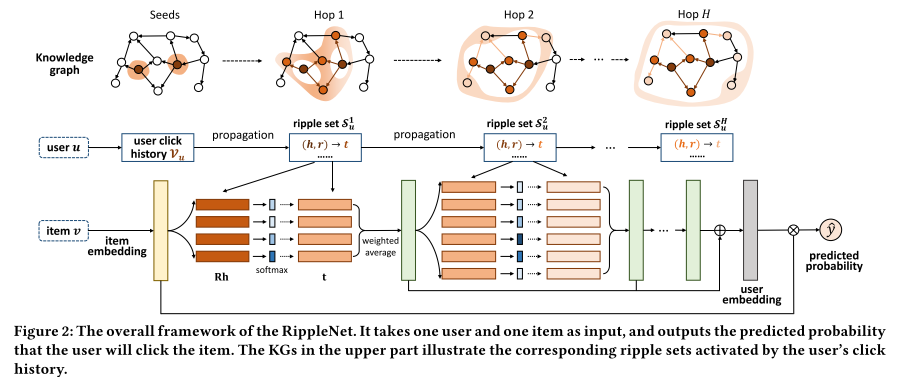
RippleNet: 将知识图谱作为额外信息,融入到CTR/Top-K推荐
动机
考虑到水波(Ripple)的传播,以user感兴趣的item为seed,在商品知识图谱上向外一圈一圈的扩散到其他的item,这个过程称之为偏好传播(Preference Propagation). 该模型认为外层的item同样属于用户的潜在偏好, 因此在刻画user时候,需要将其考虑进去,而不能仅仅使用观测到的items去表示user偏好。
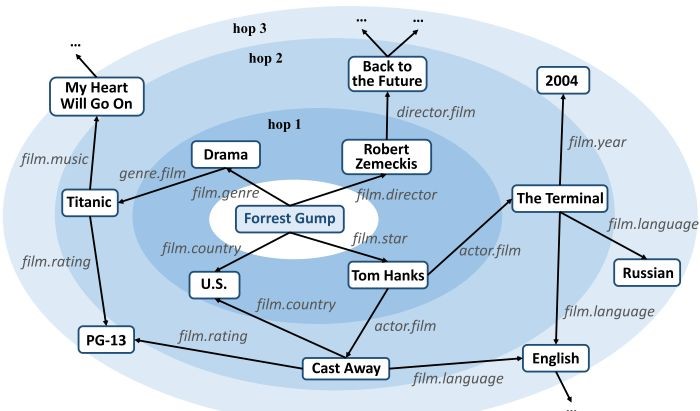
KG结合RS两种思路
- Embedding:item以及属性构建知识图谱,然后利用KG Embedding,计算item 的Embedding.
- Path-Based: 将user-item以及属性构建异质信息网络(HIN), 然后利用HIN相关的算法建模(Metapath)
一般情况,KG 只能考虑item,而HIN可以考虑user+item. 下面简要介绍下模型部分。
模型介绍
- 输入: 一个user u 和一个候选的 item i
- 输出: user会点击item的概率
- 构建 与 u 先关的 k-hop的 item 集合(知识图谱上以初始的item set向外扩展). [这些item可以作为user的偏好信息)
- 根据embedding 向量内积,计算候选item i 与 每一层hop上的head item的归一化相似度
- 根据相似度,对尾实体 items 加权求和,作为这一层hop的输出 (本质上,属于Attention,其中Q=候选item i, K=Head Item, V= Tail Item)
- 重复上述过程k次
- 将所有k hop的输出向量相加,作为user的Embedding, 与 item的Embedding 内积计算最终的相似度
总结
这篇文章动机非常直观,因此可解释性非常强,模型的构建也充满技巧,比如采样等,很多地方值的挖掘。
下面简单介绍下结合网络表示或者异质信息网络的的两篇文章。
NERM
Zhao W X, Huang J, Wen J R. Learning distributed representations for recommender systems with a network embedding approach[C]//AIRS, 2016: 224-236.
将推荐的user,item以及属性作为graph中的节点,构造网络。 之后使用network embedding的方法来学习节点特征向量, 利用相似度来做TopK推荐.
构建Graph
user, item ,feature 作为不同类型的节点, 构建网络:
- user-item的二分网络,边为user购买或者其它行为item
- user-item-tag的三分网络: 将item的tag属性加进来,也作为节点。
学习Embedding
本文完全使用LINE的一阶表示: 即对于a pair nodes (u, v) 如果 二者之间存在边,则二者的向量内积较大
推荐:
直接使用上述计算得到的user-item或者属性的 embedding, 利用内积来计算相似度,根据相似度排序来计算TopK
总览
完全使用Network Embedding的方法来做Top-N推荐,属于尝试性工作, 对比工作也很单薄。
CDNE
Gao L, Yang H, Wu J, et al. Recommendation with multi-source heterogeneous information[J]. IJCAI 2018.
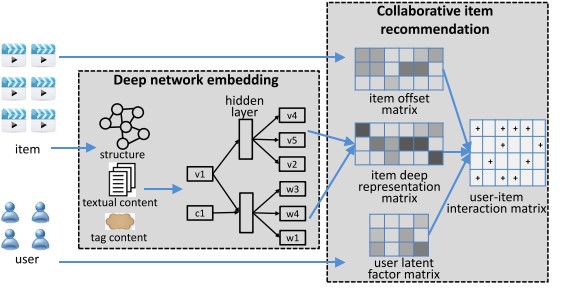
问题与CKE(fzzhang)一致:为user推荐Top N可能感兴趣的item. 利用Network Embedding的方法建模辅助信息,继而结合CF: (Network Embedding 模型基本完全参考:Tri-Party Deep Network Representation)
融合辅助信息
为了更好的建模item, 结合辅助信息:
- item的文本内容(word sequence)
- item的标签tag(也是word)
- item 与 item 的连接结构信息
Deep Walk/Skip Gram 建模辅助信息
- 模仿skip gram, 中心词预测上下文的词。这里用中心item来预测在文本内容中word,以及用item的tag来预测word
- 利用deep walk 来学习结构表示(本质上也是skip gram) 这与Tri-Party Deep Network Representation 完全一样。
这样可以学到节点的Embedding, word 的Embedding, tag的Embedding。 其中节点的Embedding用于下面的CF。
结合CF
同CKE, 将上述节点的Embedding 与CF的latent vectors 直接相加,作为item的表示向量, 用户的向量还是CF的latent vectors. 最后利用Min(R-UV) 来优化 (这里区别于CKE的pair wise ranking)
数据: 用的两份CiteULike的数据,其中 item的节点并非使用paper的reference而是根据如果有多于4个相同作者的两篇文章,那么两篇文章之间加一条边。
简要
- 方法与动机基本类似与CKE, 不过并没有对比CKE。
- 相当于CKE + Tri-DNR的结合